
Inkinen J., Lehtinen M. & Suominen O. (2023). Annifin ehdotusten osuvuus on parantunut Theseus-julkaisuarkistossa. Tietolinja, 2023(1). Pysyvä osoite: https://urn.fi/URN:NBN:fi-fe2023062865282

Sisällönkuvailuun on voinut saada apua tekoälyä hyödyntävältä Annif-ohjelmistolta jo muutaman vuoden ajan. Testaustarkoituksiin Annif on ehdottanut käsitteitä vuodesta 2018 alkaen annif.org-sivuston kautta, ja tuotantokäyttöä varten ehdotuksia on keväästä 2020 alkaen tarjonnut halukkaille Finto AI -palvelu. Vuoden 2023 alkuun asti kuvailtavan dokumentin pystyi syöttämään Finto AI -palveluun vain tekstinä, mutta nyt dokumentin voi syöttää palveluun myös tiedostona tai käyttämällä dokumentin URL-osoitetta. Finto AI:n pystyy integroimaan muihin tietojärjestelmiin sen rajapinnan avulla. Integraatio on käytössä useiden julkaisuarkistojen syöttölomakkeissa toimintoa varten, joka hakee käsite-ehdotukset syötettävälle dokumentille (Moubarik 2020). Ehdotukset saatuaan syöttölomakkeen käyttäjä sitten hyväksyy haluamansa niistä ja voi myös lisätä muita käsitteitä. Ensimmäisenä, vuonna 2018, tällainen integraatio toteutettiin Jyväskylän yliopiston JYX-julkaisuarkistossa (Häyrinen 2019), ja vuonna 2020 Osuva-, Theseus- ja Trepo-arkistoissa. Nyt integraatio on olemassa myös ainakin Taju- ja Lauda-arkistoissa, Suomen Pankin Kaisu-arkistossa sekä Kansalliskirjaston E-vapaakappaleiden luovutuslomakkeessa. Myös museoiden Collecte-järjestelmässä hyödynnetään Finto AI -integraatiota.
Kansalliskirjaston Annif-tiimi on jatkanut Annifin ja Finto AI:n säännöllistä kehitystä: olemme julkaisseet uusia Annif-versioita muutamien kuukausien välein ja tehneet päivityksiä Finto AI:ssa kahdesti vuodessa. Annif-julkaisuissa on muun muassa otettu käyttöön uusia algoritmeja ja toimintoja sekä parannettu suorituskykyä. Finto AI:n päivityksissä koneoppimismallit on koulutettu uudelleen laajemmilla ja tuoreemmilla aineistoilla ja taustalla toimiva Annif on päivitetty uusimpaan versioonsa.
Annifin toiminta perustuu koneoppimiseen, mikä tarkoittaa, että Annifilla voi luoda eli ”kouluttaa” jonkin algoritmin ja koulutusaineiston avulla mallin. Koulutusaineisto koostuu suuresta määrästä tekstidokumentteja ja niitä asiasanojen tapaan kuvaavia käsitteitä – käsitteet kullekin dokumentille on valinnut ihminen. Koulutetun mallin avulla Annifilla voi sitten tuottaa käsite-ehdotuksia uusille tekstidokumenteille.
Annif-malli tarjoaa käsite-ehdotuksia jostain tietystä sanastosta, ja haluttaessa kouluttaa Annif-malli jollekin sanastolle tarvitaan juuri tällä sanastolla kuvailtua koulutusaineistoa. Tällä hetkellä Finto AI -palvelussa on tarjolla YSO-sanastoa käyttävät valmiiksi koulutetut mallit suomen-, ruotsin- ja englanninkielisille teksteille.
Finto AI:n Annif-mallien tuottamien käsite-ehdotusten laatu on säännöllisesti parantunut päivitysten myötä. Laadun mittaamisessa olemme käytettäneet testiaineistoja, jotka koostuvat dokumenteista ja niihin liitetyistä käsitteistä samaan tapaan kuin koulutusaineistotkin. Laadun mittauksessa Annifin dokumentille tuottamia käsite-ehdotuksia verrataan ihmisen sille liittämiin käsitteisiin, ja vertailun perusteella lasketaan lukuarvot erilaisille samankaltaisuusmittareille kuten saanti, tarkkuus ja F1-arvo. Näiden määritelmät selvitetään myöhemmin tässä tekstissä.
Laadun mittaaminen vertaamalla mallin tuotoksia etukäteen kerättyihin testiaineistoihin on perustavanlaatuinen menetelmä koneoppimisjärjestelmiä kehitettäessä, mutta on mielenkiintoista ja tärkeää seurata näiden järjestelmien tuloksia myös todellisessa käytössä. Aiheesta kiinnostuneille vinkkinä: automaattisen asiasanoituksen laadun arviointia ovat ansiokkaasti käsitelleet Golub et al. (2016). Tätä artikkelia varten olemme keränneet aineiston Annifin ehdottamista ja käyttäjän valitsemista käsitteistä Theseus-julkaisuarkistoon syötetyistä dokumenteista. Aineisto perustuu suomenkielisiin dokumentteihin, jotka on syötetty syyskuun 2020 ja maaliskuun 2023 välillä ja joille on olemassa sekä Annifin ehdotukset että käyttäjän valitsemat käsitteet. Dokumentteja on noin 44 000, ja ne ovat pääasiassa AMK-opinnäytetöitä; vain noin tuhat dokumenttia on muuta tyyppiä. Syöttölomakkeen käyttäjä on yleensä ollut opinnäytetyön kirjoittaja. Aineisto perustuu vain suomenkielisiin dokumentteihin, koska muun kielisiä Theseukseen ei juuri ole syötetty.
Annifin käyttöä Theseus-julkaisuarkistossa on tutkittu myös aiemmin (Tolonen 2021). Tuolloin on analysoitu Annifin ehdotuksia lukuvuoden 2020–2021 ajalta 200 dokumentin otoksen avulla.
Samankaltaisuusmittarit
Tässä alaluvussa käydään lyhyesti läpi samankaltaisuusmittarien tarkkuus, saanti ja F1-arvo määritelmät tämän artikkelin asiayhteydessä. Kukin mittari voi saada arvoja nollan ja yhden välillä. Theseuksen syöttölomakkeessa käyttäjälle näytetään (enintään) 10 ehdotusta, joten varsinaisesti nämä mittarit ovat niin kutsuttuja @10-mittareita, joita laskettaessa huomioidaan vain 10 algoritmin parhaaksi arvioimaa ehdotusta.
Tarkkuus (precision)
Dokumenttikohtainen tarkkuus on oikeiden ehdotusten (so. käyttäjän hyväksymien) osuus kaikista ehdotuksista (yleensä 10 kpl). Suuri tarkkuuden arvo tarkoittaa, että suuri osa Annifin ehdotuksista sopii käyttäjän mielestä dokumentille.
Saanti (recall)
Dokumenttikohtainen saanti on oikeiden ehdotusten osuus kaikista oikeista käsitteistä eli käyttäjän hyväksymistä Annifin ehdotuksista ja käyttäjän itsensä lisäämistä käsitteistä. Suuri saannin arvo tarkoittaa, että Annifin ehdotuksista jää käyttäjän mielestä puuttumaan vain vähän dokumentin oikeita käsitteitä (jolloin käyttäjä lisää itse vain vähän käsitteitä ehdotusten lisäksi).
F1-arvo (F1-score)
F1-arvo on tarkkuuden ja saannin harmoninen keskiarvo. Se on tyypillinen mittari, jota koneoppimisjärjestelmissä pyritään optimoimaan. F1-arvo on yksi, jos sekä tarkkuus että saanti ovat yksi, ja nolla, jos joko tarkkuus tai saanti on nolla.
Ehdotusten laadun kehitys
Kuvassa 1 on kuukausittainen keskiarvo tarkkuudesta, saannista ja F1-arvosta. Pystykatkoviivoin on merkitty ajankohdat, jolloin Finto AI:n mallit on päivitetty. Kuvaajasta käy ilmi ehdotusten laadun parantuminen ajan myötä, mutta kovin selvää yhteyttä päivitysajankohtiin ei ole nähtävissä. F1-arvo on keskimäärin ennen ensimmäistä merkittyä mallipäivitystä 0,54, ja viimeisen mallipäivityksen jälkeen 0,62: muutos on 0,08. Näitä lukuja voidaan verrata samojen malliversioiden F1@5-arvoihin JYX-julkaisuarkiston testiaineistolla laskettuna; ne ovat 0,43 ja 0,53: muutos on 0,10.
On huomattava, että kuukausittain syötettyjen dokumenttien määrä vaihtelee paljon, kuten kuvasta 2 on nähtävissä. Heinäkuussa 2021 ja 2022 dokumentteja on syötetty hyvin vähän, minkä vuoksi mittarien arvot näinä kuukausina eivät ole yhtä luotettavia kuin muulloin.
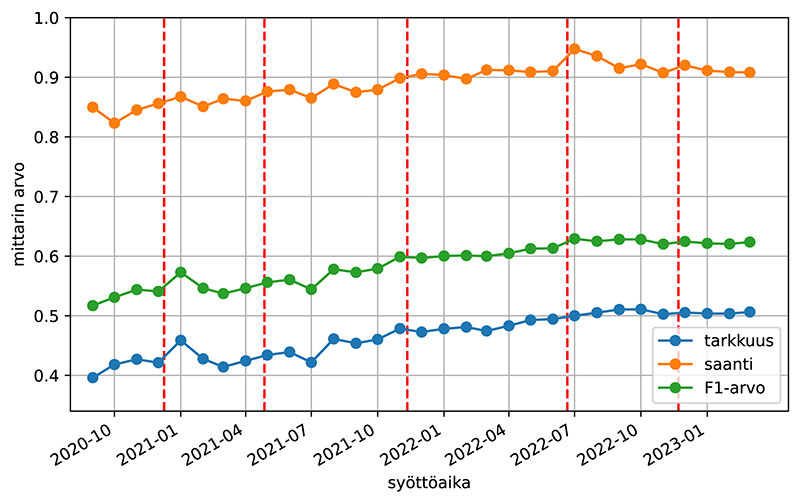
Kuva 1. Samankaltaisuusmittarien kuukausittainen keskiarvo. Finto AI -palvelun mallien päivitysten ajankohdat on merkitty pystykatkoviivoin.
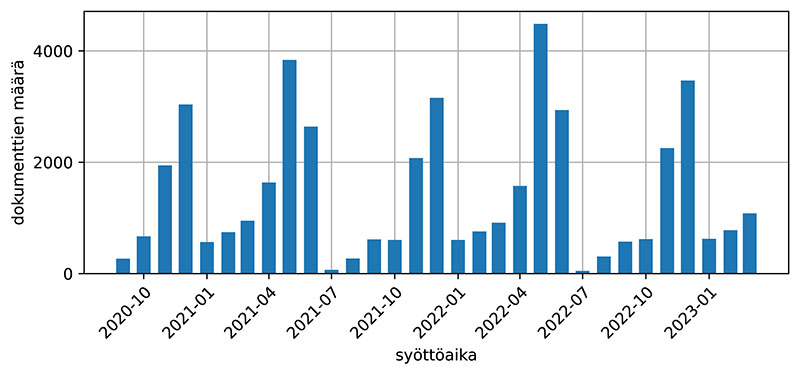
Kuva 2. Syötettyjen dokumenttien määrä aineistossa kuukausittain.
Ehdotusten tarkkuuden ja saannin jakauma
Samankaltaisuusmittarien kuukausittaisten keskiarvojen avulla voidaan seurata laadun yleistä kehitystä, mutta vain keskiarvoja tarkastelemalla jää havaitsematta monia aineiston olennaisia piirteitä. Kuvassa 3 esitetään tarkkuuden ja saannin arvojen jakauma koko aineistossa. Jakaumat kertovat, kuinka monen dokumentin ehdotusten saanti ja tarkkuus on milläkin arvovälillä. Jakaumat sisältävät siten enemmän tietoa kuin keskiarvot, jotka yhdellä luvulla kuvaavat tarkkuutta ja saantia, mutta eivät kerro mitään näiden vaihtelusta keskiarvon ympärillä. Jakaumista voidaankin tehdä tarkempia havaintoja ehdotusten osuvuudesta.
Tarkkuuden jakauma näyttää, että käyttäjät ovat yleisimmin hyväksyneet 3 tai 4 ehdotusta 10:stä. Aineistossa 1976 dokumentin tapauksessa käyttäjä on hyväksynyt kaikki ehdotukset, ja tästä joukosta 1643 dokumentille (3,7 % kaikista dokumenteista) käyttäjä ei ole itse lisännyt yhtään käsitettä, eli Annifin ehdotukset on sellaisenaan hyväksytty dokumentin kuvailuksi.
Saannin jakauma on puolestaan kasautunut lähes täysin suurimman arvon pylvääseen. Useimpien dokumenttien tapauksessa (30541 dokumenttia; 69 % osuus) käyttäjä ei ole lisännyt yhtäkään käsitettä ehdotusten lisäksi. Kaikki ehdotukset on hylätty 431 dokumentin tapauksessa (1,0 % osuus).
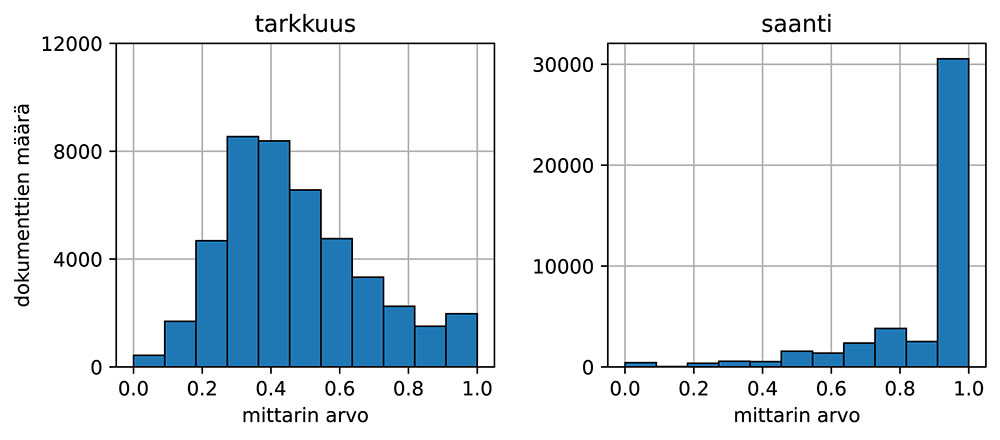
Kuva 3. Tarkkuuden ja saannin jakaumat.
Edellä esitettyjen huomioiden perusteella vaikuttaa siltä, että ollaan varsin kaukana kauhuskenaariosta, missä käyttäjät hyväksyvät kaikki Annifin ehdotukset ilman harkintaa, mikä voisi olla epätoivottu seuraus Annif-integraatiosta. Epäselvempää on, mikä vaikutus on sillä, että käyttäjät vain hyvin harvoin lisäävät käsitteitä ehdotusten lisäksi. Syy vähäiseen lisäyksien määrään voi toki olla se, että ehdotukset ovat jo valmiiksi riittävän kattavia ja monipuolisia.
Käsitteiden lukumäärä
Voi olettaa, että Annif-integraatio vaikuttaa dokumentteihin liitettyjen käsitteiden lukumäärään, ja aineiston perusteella näin vaikuttaa olevankin: ennen integraatiota (toukokuusta elokuuhun vuonna 2020) Theseukseen syötettyihin dokumentteihin liitettiin 3,7 +- 1,9 käsitettä ja integraation jälkeen 5,3 +- 2,4 käsitettä (keskiarvo +- keskihajonta). Näitä arvoja laskettaessa on huomioitu vain dokumentit, joihin on liitetty vähintään yksi käsite.
Vaikuttaa siis siltä, että Annifin ehdotusten tarjoaminen käyttäjälle lisää dokumenttiin liitettävien käsitteiden määrää. Koska käsitteiden määrä on edelleenkin vähäinen, lisäyksellä voi olettaa olevan pääasiassa myönteisiä seurauksia kuvailujen kattavuuden parantuessa. Luultavasti käsitteiden lukumäärän kasvuun vaikuttaa tosin myös integraation kanssa samaan aikaan tapahtuneet muut muutokset syöttölomakkeessa ja käyttäjien ohjeistuksessa.
Ehdotukset aloittain
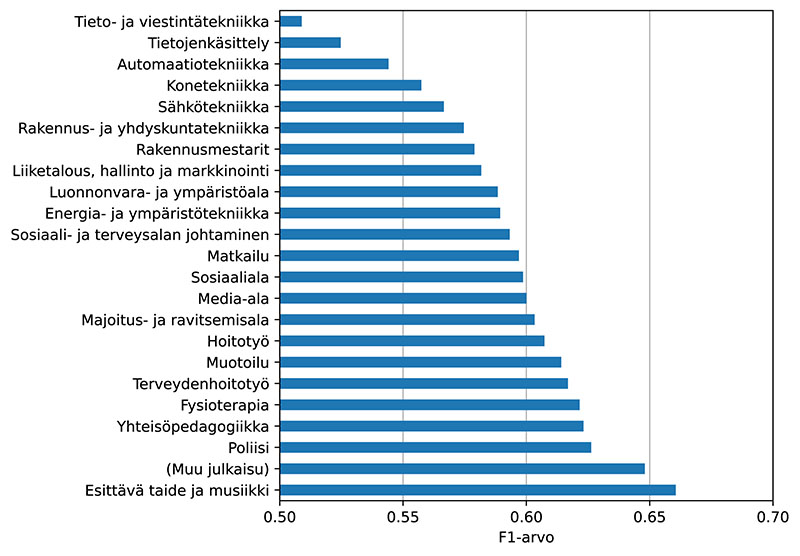
Kuva 4. Keskimääräiset F1-arvot niiltä koulutusaloilta, joille dokumentteja on syötetty vähintään 500.
Annifin ehdotusten osuvuuteen vaikuttaa paljon dokumentin tyyppi ja aihepiiri. Aiemmin tekemiemme kokeiden perusteella tiedämme, että kaunokirjallisuus on Annifille huomattavasti vaikeampi alue kuin asiatekstit, ja asiatekstien tapauksessa ehdotusten osuvuuteen vaikuttaa tekstin aihepiiri.
Kuvassa 4 on keskimääräinen F1-arvo aineistosta koulutusaloittain (degree program). Kuvasta on nähtävissä sama kuin on aiemmin havaittu Annifin ehdotuksissa JYX-julkaisuarkistossa: ehdotukset ovat huonoiten sopivia teknisillä aloilla (Suominen 2019). Tämä saattaa olla seurasta eroista eri alojen käsitteiden laajuudessa: teknisiin aloihin liittyvät käsitteet voivat olla spesifimpiä kuin esimerkiksi humanistisiin aloihin liittyvät. Muiden julkaisutyyppien kuin opinnäytetöiden (“Muu julkaisu”) osalta Annifin ehdotukset ovat käsittelemässämme aineistossa hyvin osuvia.
Yhteenveto
Sisällönkuvailun laatu ei ole tarkasti määritelty ominaisuus. Koneoppimisjärjestelmien yhteydessä käytetyt mittarit tarkkuus, saanti ja F1-arvo perustuvat mallin ennustusten vertaamiseen oikeaksi määriteltyihin vastauksiin. Tässä artikkelissa näiden mittarien arvoja laskettaessa Annifin ehdotuksia verrattiin käyttäjän dokumentille oikeina pitämiin käsitteisiin. Oikeiden käsitteiden valinta ei suinkaan ole yksiselitteistä: aiemmissa kokeissa on havaittu eri henkilöiden samalle dokumentille valitsemien käsitteiden yhdenmukaisuuden olevan 30–50% (Medelyan 2009). Mittareiden lukuarvoista sinällään ei siis voi päätellä paljoakaan, mutta niiden kasvu kuitenkin osoittaa Annifin ehdotusten osuvuuden parantuneen.
Olemme aiemmin arvioineet Annifin ehdotusten laatua joukkoistuksen avulla Kirjastoverkkopäivillä vuosina 2017, 2019 ja 2021. Kahden viime kerran työpajoissa osallistujat pisteyttivät eri tavoin tuotettuja sisällönkuvailuja tarkastelemalla niitä ja kuvailtavaa dokumenttia (Lehtinen 2019, Inkinen 2021). Vuoden 2021 työpajassa Annifin parhaan algoritmin tuottamat sisällönkuvailut arvioitiin keskimäärin paremmiksi kuin julkaisuarkistoista kerätyt kuvailut. Sisällönkuvailun ammattilaisten tuottamat kuvailut voittivat kuitenkin algoritmien kuvailut. Myös syksyn 2023 Kirjastoverkkopäivillä on luvassa ohjelmaa automaattisesta kuvailusta.
Kreodi-lehden artikkelissa (Tolonen 2021) analysoitiin Annifin ehdotuksia Theseus-julkaisuarkistossa lukuvuoden 2020–2021 ajalta 200 dokumentin otoksen avulla. Artikkelissa todettiin Annifin käytön olevan hyödyllistä, ja vaikka kaikki ehdotukset eivät aina olleetkaan opinnäytteelle lainkaan sopivia, syöttölomaketta käyttäneet opiskelijat jättivät ne valitsematta.
Tämä artikkeli toivottavasti selventää automaattisen sisällönkuvailun menetelmien käyttöönoton vaikutuksia julkaisuarkistoissa ja vastaavissa kohteissa. Annifin ehdotusten osuvuuden parantuminen sekä Theseus-julkaisuarkistossa että testiaineistoilla lisää varmuutta siitä, että käyttämämme testiaineistot soveltuvat yleiseen sisällönkuvailun laadun arviointiin. Tulevaisuudessa laajennamme Finto AI -palvelun sanastovalikoimaa sekä jatkamme Annifin ja Finto AI:n kehitystä kohti entistä osuvampia ehdotuksia ja parempaa käytettävyyttä.
Kiitämme Samu Viitaa ja Anis Moubarikia avusta aineiston keräämisessä!
Lähteet ja viitteet
Tässä artikkelissa käytetyn aineiston analyysi Jupyter Notebook -tiedostossa: https://github.com/NatLibFi/FintoAI-data-YSO/blob/main/repository-metrics-analysis/analyse-theseus-tietolinja.ipynb
Moubarik, A. (2020). Demo Annif-ehdotuksista syöttölomakkeella (Videotallenne): http://urn.fi/URN:NBN:fi-fe2020042219855
Häyrinen, A. (2019). Annif oikeissa töissä – miten Annifia käytetään JYU:n Avoimen tiedon keskuksessa. Ari Häyrisen esitys Kirjastoverkkopäivillä 23.10.2019 Helsingissä. http://urn.fi/URN:NBN:fi-fe2019120445632
Golub, K., Soergel, D., Buchanan, G., Tudhope, D., Hiom, D., and Lykke, M. (2016). A framework for evaluating automatic indexing or classification in the context of retrieval. Journal of the Association for Information Science and Technology. 67(1), 3-16. https://doi.org/10.1002/asi.23600
Tolonen, T. (2021). Annif asiasanoittajana – kokemuksia Theseuksesta. Kreodi, 2021(3). http://urn.fi/URN:NBN:fi-fe2021060634290
Suominen, O. (2019). Annif: DIY automated subject indexing using multiple algorithms. LIBER Quarterly, 29(1), 1–25. http://doi.org/10.18352/lq.10285
Medelyan, O. (2009). Human-competitive automatic topic indexing (Doctoral dissertation, The University of Waikato). https://researchcommons.waikato.ac.nz/handle/10289/3513
Lehtinen, M., Inkinen, J. & Suominen, O. (2019). Aaveita koneessa: Automaattisen sisällönkuvailun arviointia Kirjastoverkkopäivillä 2019. Tietolinja, 2019(2). http://urn.fi/URN:NBN:fi-fe2019120445612
Inkinen J., Lehtinen M. & Suominen O. (2021). Automaattisen kuvailun arvoituksia Kirjastoverkkopäivillä 2021. Tietolinja, 2021(2). https://urn.fi/URN:NBN:fi-fe2021121661232
Kirjoittajat
Juho Inkinen, tietojärjestelmäasiantuntija
Mona Lehtinen, tietoasiantuntija
Osma Suominen, tietojärjestelmäasiantuntija
Kaikki kirjoittajat työskentelevät Kansalliskirjastossa. Heidät tavoittaa sähköpostitse, ja sähköpostit ovat muotoa etunimi.sukunimi [at] helsinki.fi
Juha Hakala
Keskustelin Annifista ulkomaisessa tieteellisessä kirjastossa työskentelevän kollegan kanssa. Hän on sovelluksesta kiinnostunut, ja kertonut siitä kollegoilleen. IT-osaston vastaus oli kuitenkin se, ettei Annifin käyttöönottoon ole resursseja. Miten paljon niitä tarvittaisiin? Ja mitä mahdollisuuksia Kansalliskirjastolla on tukea käyttöönottoja muualla?
Mona Lehtinen
Hienoa kuulla, että Annif kiinnostaa! Annifin käyttöönoton resussitarve vaihtelee tapauksesta riippuen, joten aivan tarkkaa vastausta on hankala antaa. Tietyt työvaiheet käyttöönotoissa kuitenkin toki on: Annif tarvitsee ensinnä (kuratoitua) koulutusdataa, jonka hankkiminen saattaa olla aikaavievää. Koneoppimismallien koulutus ja laadun arviointi kerätyn datan perusteella sujunee melko sujuvasti, kunhan siihen on henkilöresursseja. Annifin mahdollinen integrointi muihin järjestelmiin on seuraava vaihe, johon taas vaaditaan henkilöresursseja. Tämän jälkeen voidaan siirtyä ylläpitovaiheeseen.
Kansalliskirjasto voi tukea käyttöönottoja jossain määrin, esim. neuvomalla. Myös maksullisen palvelun mallia on suunniteltu niihin tapauksiin, joissa tukea / työtä tarvitaan meiltä enemmän. Joka tapauksessa näistä pitäisi sitten keskustella tapauskohtaisesti. Meihin voi aina olla yhteydessä Annifin tiimoilta!