
Liukkonen E, Pääkkönen T & Kaukonen M (2021) ”Turho hölyhtys” on nyt ”turha hälyytys”. Digitoidun sanomalehtiaineiston sisältöhaun parannukset käytössä. Tietolinja 2021(2). Pysyvä osoite: https://urn.fi/URN:NBN:fi-fe2021121661233
![]()
Kansalliskirjaston koko vanhin digitoitu sanomalehtiaineisto vuosilta 1771–1914 käsitellään uudestaan siten, että sen tekstintunnistus ja samalla tekstiin kohdistuvien hakujen osuvuus paranevat merkittävästi. Tekstintunnistus on erittäin oleellinen osa digitoitujen historian lähdeaineistojen laatua ja käytettävyyttä. Sanomalehtikokoelman kielet ovat suomi ja ruotsi. Parempilaatuinen aineisto on saatettu käytettäväksi vaiheittain kesästä 2021 alkaen ja käyttöön on saatettu marraskuun loppuun mennessä noin 90 % lehdistä.
Myös valikoima vuosien 1915–1918 tutkimukselle ja yhteiskunnalle keskeisiä lehtiä saatetaan käyttöön uudelleen käsiteltyinä: lehtinimekkeet ovat Uusi Aura, Uusi Suometar, Helsingin Sanomat, Åbo Underrättelser, Västra Finland ja Hufvudstadsbladet.
Yhteensä parempilaatuista sanomalehtimateriaalia tulee saataville lähes 2,5 miljoonaa sivua digi.kansalliskirjasto.fi:hin. Kansalliskirjasto suunnittelee myös osaan muista 1910-luvulla ilmestyneistä sanomalehdistä uutta tekstintunnistusta.
Sisältöhakujen osuvuus paranee merkittävästi
Aiempiin tekstintunnistuksen tuloksiin verrattuna uudelleen käsitellyn aineiston laatu on huomattavasti parempaa, laatu on kohentunut keskimäärin 17 prosenttiyksikön verran. Tekstintunnistuksessa on käytetty apuna Transkribus-alustaa, joka on alun perin kehitetty käsin kirjoitetun tekstin tunnistamiseen, mutta sitä on menestyksekkäästi sovellettu myös painettuun aineistoon Horizon 2020 -ohjelmasta rahoitetussa NewsEye-projektissa. Kansalliskirjasto on projektissa mukana.
Sanomalehtiaineiston tekstintunnistuksen parannukset kohdistuvat vanhempaan kirjaintyyppiin fraktuuraan, jonka tunnistuskyvykkyys Transkribuksessa on parempaa kuin aiemmin käytössä olleissa ohjelmissa. Kuvan 1 esimerkissä aiempi teksti “Turho hölyhtys” on nyt tunnistettu oikein “Turha hälyytys”, ja myös koko kappaleen teksti on luettavampaa aiempaan verrattuna. Vanhassa tekstikappaleessa omorfi-työkalu tunnistaa sanoiksi 59 % ja uudessa 75 %, joten muutos on näinkin lyhyessä tekstissä jo huomattava. NewsEye-projektissa kehitetyssä tekstintunnistuksen ATR-algoritmissa on päästy alle 1 % merkkivirhetasoon (Michael & Labahn, 2020), jonka hyödyt näkyvät Kansalliskirjaston aineistossa. Sanomalehtiaineiston laadun arvioinnissa hyödynnetty Omorfi on avoimen lähdekoodin morfologinen jäsennin suomen kielelle ja sillä on mahdollista analysoida suomenkielistä tekstiä. Omorfin sisältämistä työkaluista omorfi-analyse-text.sh työkalua on hyödynnetty sivuluottamusarvojen (PC) laskennassa.
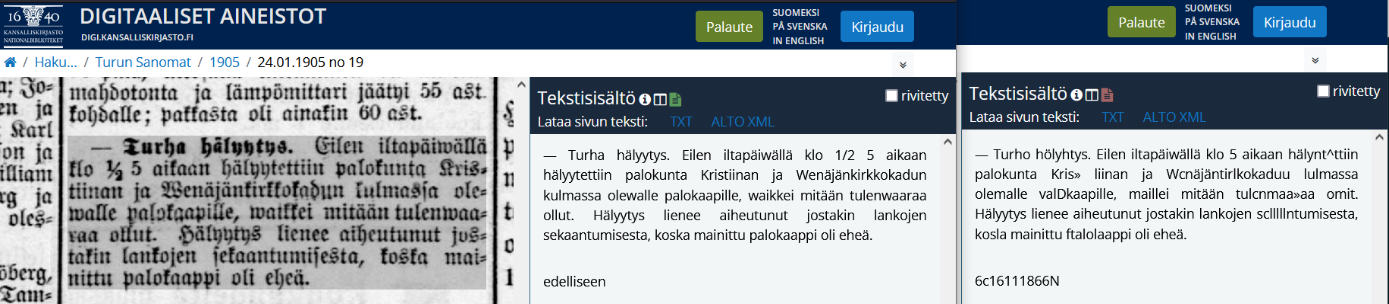
Kuva 1. Turun Sanomat 24.01.1905 no 19, vierekkäin sivukuva, uusi ja vanha tunnistettu teksti.
Transkribuksella käsitellyille sivuille on laskettu sivuluottamusarvo (PC), joka kertoo, mikä osuus sivun sanoista on tunnistettu oikeiksi. Sivuluottamusarvojen laskenta suoritettiin omorfin versiolla, joka käsittelee parhaiten vanhaa suomen kieltä. Noin miljoonan sivun osalta arvot vaihtelevat 0,7–0,9 välillä, mikä myös osoittaa, että tekstintunnistus on hyvällä tasolla. Sivuluottamusarvo näkyy digi.kansalliskirjasto.fi:hin viedyissä sivuissa ALTO XML -tiedostomuodossa sivutunnisteen kanssa samalla rivillä:
<Page ID=”Page1″ PHYSICAL_IMG_NR=”1″ HEIGHT=”6279″ WIDTH=”4465″ PC=”0.884”>.
Kiinnostavaa sivuluottamusarvossa on, että se ei näytä vaihtelevan merkittävästi, vaikka eri vuosien aineistojen laadussa on eroa. Myöskään lehtien erilaisella sivurakenteella ei tämän vertailuarvon perusteella näytä olevan negatiivista vaikutusta tekstin tunnistuksen osuvuuteen.
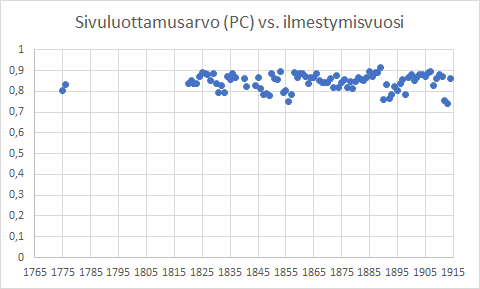
Kuva 2. Sivuluottamusarvot suhteessa ilmestymisvuosiin.
Parempilaatuisen OCR:n sivuluottamusarvot ovat keskimäärin noin 17 prosenttiyksikköä parempia Helsingin Sanomista kootun vertailuaineiston perusteella (Taulukko 1). Myöskään minkään vertailuaineiston niteen kohdalla uuden aineiston sivuluottamusarvot eivät olleet heikompia aikaisempaan verrattuna. Vertailuaineisto muodostuu 15 Helsingin Sanomien niteestä tammikuulta 1918. Aineiston sivujen tekstityyppinä on enimmäkseen antiikva. Niteiden sisältämien sivujen sivuluottamusarvojen keskiarvot on laskettu sekä uudelle että aikaisemmalle aineistolle.
| Helsingin sanomat 1918 (15 nidettä) | Uusi PC | Aikaisempi PC | Erotus |
| 1 | 0,905875 | 0,747375 | 0,1585 |
| 2 | 0,889 | 0,7405 | 0,1485 |
| 3 | 0,8963 | 0,7555 | 0,1408 |
| 4 | 0,8842 | 0,6872 | 0,197 |
| 5 | 0,8819 | 0,719 | 0,1629 |
| 6 | 0,8845625 | 0,7230625 | 0,1615 |
| 7 | 0,908833333 | 0,700666667 | 0,208166667 |
| 8 | 0,8853 | 0,7052 | 0,1801 |
| 9 | 0,8927 | 0,7202 | 0,1725 |
| 10 | 0,8858 | 0,7141 | 0,1717 |
| 11 | 0,897 | 0,7437 | 0,1533 |
| 12 | 0,89975 | 0,730166667 | 0,169583333 |
| 13 | 0,8926875 | 0,7400625 | 0,152625 |
| 14 | 0,909333333 | 0,695166667 | 0,214166667 |
| 15 | 0,883083333 | 0,693583333 | 0,1895 |
| Keskiarvo | 0,893088333 | 0,721032222 | 0,172056111 |
Taulukko 1. Helsingin Sanomien sivuluottamusarvojen vertailu aikaisemman ja uuden aineiston välillä.
Kuvasta 3 on myös havaittavissa, että uuden parempilaatuisen aineiston sivuluottamusarvoissa on huomattavasti vähemmän vaihtelua niteiden välillä verrattuna alkuperäiseen aineistoon.
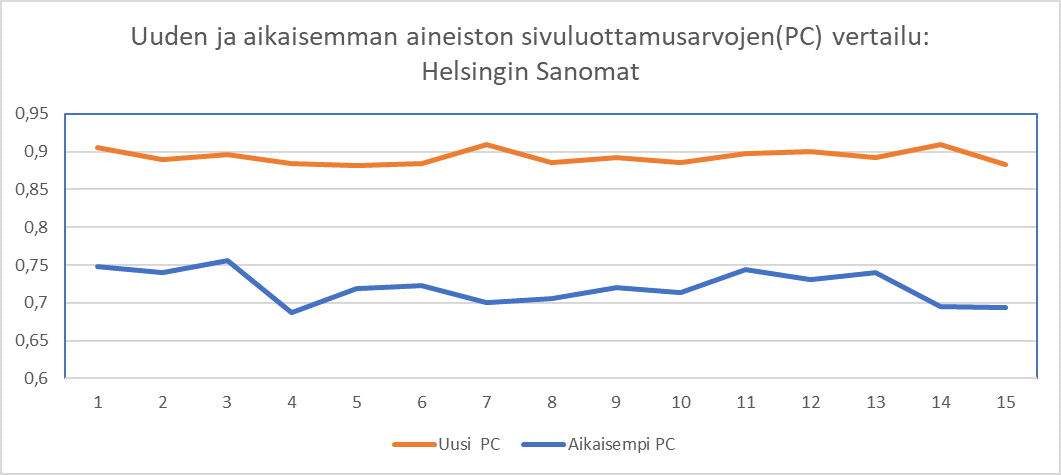
Kuva 3. Helsingin Sanomista kootun vertailuaineiston sivuluottamusarvot (PC) esitettynä kaaviossa. Asteikko havainnollistaa aineistojen laadun tasoittumista.
Myös Aamulehdestä kootun vertailuaineiston perusteella uuden parempilaatuisen aineiston sivuluottamusarvot ovat keskimäärin noin 17 prosenttiyksikköä parempia (Taulukko 2). Myös Aamulehden niteiden uuden aineiston sivuluottamusarvot olivat kaikilta osin paremmat verrattuna aikaisempaan aineistoon. Sivuluottamusarvot ovat myös hyvin lähellä Helsingin Sanomien aineistolla saatuja arvoja, vaikka aineistossa käytetään eri kirjasinta ja se on eri vuodelta. Aamulehden vertailuaineisto muodostuu 25 niteestä tammikuulta 1897, ja sivujen kirjasimena on pääosin fraktuura. Jokaiselle niteelle on laskettu sen sisältämien sivujen sivuluottamusarvojen keskiarvot sekä uudelle että aikaisemmalle aineistolle.
| Aamulehti 1897 (25 nidettä) | Uusi PC | Aikaisempi PC | Erotus |
| 1 | 0,9075 | 0,7465 | 0,161 |
| 2 | 0,88575 | 0,70825 | 0,1775 |
| 3 | 0,89825 | 0,75 | 0,14825 |
| 4 | 0,89225 | 0,73725 | 0,155 |
| 5 | 0,916 | 0,7655 | 0,1505 |
| 6 | 0,9025 | 0,756 | 0,1465 |
| 7 | 0,90425 | 0,762 | 0,14225 |
| 8 | 0,90975 | 0,757 | 0,15275 |
| 9 | 0,91575 | 0,74375 | 0,172 |
| 10 | 0,89325 | 0,69475 | 0,1985 |
| 11 | 0,896 | 0,7425 | 0,1535 |
| 12 | 0,90625 | 0,73525 | 0,171 |
| 13 | 0,903 | 0,7275 | 0,1755 |
| 14 | 0,91475 | 0,7195 | 0,19525 |
| 15 | 0,90175 | 0,702 | 0,19975 |
| 16 | 0,907 | 0,74425 | 0,16275 |
| 17 | 0,913 | 0,715 | 0,198 |
| 18 | 0,9165 | 0,7605 | 0,156 |
| 19 | 0,90625 | 0,70175 | 0,2045 |
| 20 | 0,90025 | 0,7065 | 0,19375 |
| 21 | 0,90875 | 0,7515 | 0,15725 |
| 22 | 0,90425 | 0,73675 | 0,1675 |
| 23 | 0,91175 | 0,73325 | 0,1785 |
| 24 | 0,91625 | 0,76025 | 0,156 |
| 25 | 0,89925 | 0,7355 | 0,16375 |
| Keskiarvo | 0,90521 | 0,73572 | 0,16949 |
Taulukko 2. Aamulehden sivuluottamusarvojen vertailu aikaisemman ja uuden aineiston väillä.
Kuvasta 4 voidaan myös havaita Aamulehdestä kootun uuden parempilaatuisen aineiston sivuluottamusarvojen sisältävän vähemmän vaihtelua niteiden välillä verrattuna alkuperäisestä aineistosta laskettuihin sivuluottamusarvoihin.
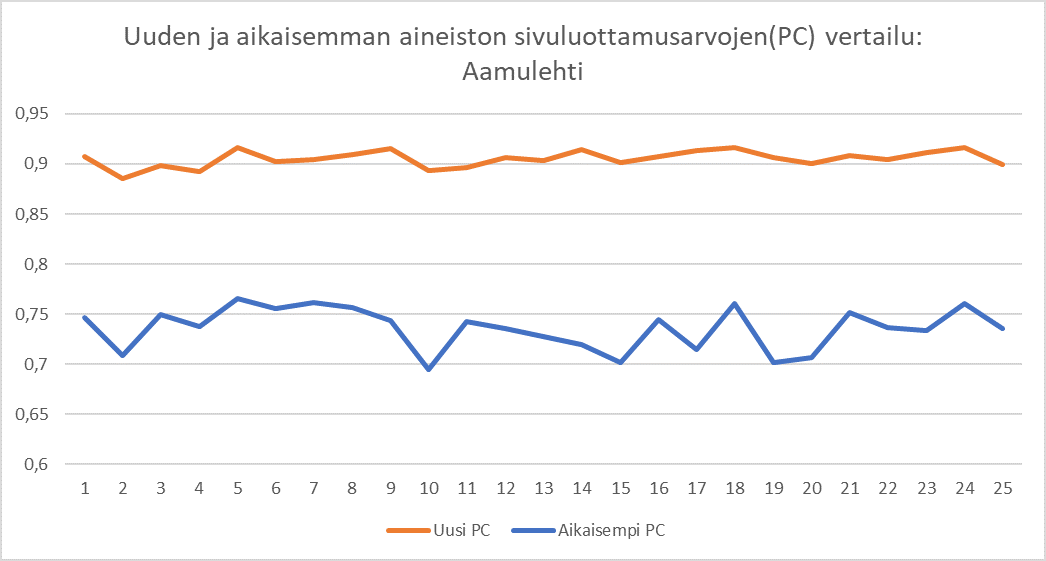
Kuva 4. Aamulehdestä kootun vertailuaineiston sivuluottamusarvot (PC) esitettynä kaaviossa. Asteikko havainnollistaa aineistojen laadun tasoittumista.
Koska hakujen kohteena oleva aineisto ja sen indeksointi eli tekstihaun perusta muuttuvat, myös haun tulokset muuttuvat. Esimerkiksi tietyllä hakusanalla tehty haku voi tuottaa aiemmasta poikkeavan määrän tuloksia.
Parhaimmillaan parempilaatuinen teksti edistää uusien hakutulosten löytämistä, kun aiemmin tekstintunnistusvirheiden takia salaisuudeksi jäänyt teksti osuu nyt tekstihakuun. Sumea tekstihaku on toki auttanut näissä aiemminkin, mutta kaikkein virheellisimpiin tunnistusmuotoihin sekään ei aina ole voinut tarttua. Esimerkiksi lause “Kissa lciIkk’ t1en vI.” voi nyt muuttua muotoon “Kissa loikk1 tien yli”. Haussa pyritään aina automaattisesti korjaamaan kaksi merkkimuutosta hakusanoissa, joten jälkimmäisen tapauksessa “kissa loikki” haku antaa tuloksen, vaikka ensimmäisessä versiossa jää löytymättä. Tekstintunnistus on parempi, ja riippuen hakuehdoista lauseeseen voi nyt päätyä useammalla hakusanalla.
On hyvä huomata, että vaikka tekstintunnistus on parempaa, se ei kuitenkaan ole edelleenkään täysin virheetöntä, virheitä löytyy vielä korjatustakin versiosta. Virheitä voi olla erityisesti otsikoissa ja mainoksissa, joissa on tekstin perusrakenteesta eroavaa muotoilua, esimerkiksi suurempaa korostustekstiä tai merkkejä. Lisäksi huomasimme, että ajoittain uusi tekstintunnistus on jättänyt tiettyjä rivejä huomioimatta, jolloin ne eivät ole käytettävissä tekstihaussa.
Uudelleen tekstintunnistetun aineiston vienti digi.kansalliskirjasto.fi-palveluun
READ-COOP-osuuskunta ylläpitää Transkribus-alustaa, joka on erikoistunut erilaisten dokumenttien tekstintunnistukseen (Transkribus, 2021). Transkribuksen ATR-algoritmiin on kehitetty koneoppimismalleja jo useamman vuoden ajan (Michael & Labahn, 2020).
Kun Kansalliskirjaston aineisto oli käsitelty Transkribuksella, sille laskettiin sivuluottamusarvot omorfi-työkalulla. Tämän jälkeen tiedostot nimettiin uudelleen, jotta digi.kansalliskirjasto.fi-palvelun tuontiohjelmisto osasi yhdistää tiedostot alkuperäisiin. Tuontia suoritettiin vaiheittain, lehtinimeke kerrallaan. Uusi tekstintunnistus tulee näkyviin alkuperäisen vierelle, jolloin on mahdollista verrata aiemman ja uuden tekstintunnistuksen laatua. Jokaisen käyttäjän on mahdollista tutkia tekstintunnistuksen eroja sivutoiminnon A-ikonista avautuvalta ’Tekstisisältö’-välilehdeltä. Vihreä ikoni kertoo, että kyseessä on päivitetty OCR (tekstintunnistus) ja punainen, että kyseessä on alkuperäinen OCR-teksti.
Kuva 5. Päivitetyn tekstintunnistuksen ikoni digi.kansalliskirjasto.fi:ssä.
Kiitokset
Parempilaatuisten digitaalisten sanomalehtiaineistojen käyttöön saattaminen on tehty Digitaalinen avoin muisti -projektissa. Työssä on hyödynnetty Euroopan Unionin Horizon-ohjelman NewsEye-projektissa kehitettyä automaattisen tekstintunnistuksen mallia ja tehty yhteistyötä eurooppalaisen READ-COOP-osuuskunnan kanssa. Kansalliskirjasto on NewsEye-projektin ja READ-COOP-osuuskunnan jäsen. NewsEye-projekti (newseye.eu) on kehittänyt ohjelmallisia työkaluja digitoitujen historiallisten sanomalehtien tutkimukseen ja käyttämiseen. READ-COOP-osuuskunta (readcoop.eu) kehittää historiallisten aineistojen käytettävyyttä tekoälyn avulla.
Lähteet
Michael, J., & Labahn, R. (2020). Automatic Text Recognition (s. 13). NewsEye Report. https://cordis.europa.eu/project/id/770299/results [julkaistaan keväällä 2022]
Transkribus (2021). Haettu 30.7.2021. Saatavilla: https://readcoop.eu/transkribus/howto/how-to-transcribe-documents-with-transkribus-introduction/.
Omorfi. Haettu 20.8.2021. Saatavilla: https://github.com/jiemakel/omorfi.
Lisätietoja kirjoittajilta:
Erno Liukkonen, tietojärjestelmäasiantuntija
erno.liukkonen[at]helsinki.fi
Tuula Pääkkönen, tietojärjestelmäasiantuntija
tuula.paakkonen[at]helsinki.fi
Minna Kaukonen, suunnittelupäällikkö
minna.kaukonen[at]helsinki.fi
Kansalliskirjasto, tutkimuskirjasto
Mikkelin toimipiste
Leave a Reply