
Inkinen J, Lehtinen M & Suominen O (2021). Automaattisen kuvailun arvoituksia Kirjastoverkkopäivillä 2021.Tietolinja, 2021(2). Pysyvä osoite: https://urn.fi/URN:NBN:fi-fe2021121661232
Järjestimme Kirjastoverkkopäivillä 2021 työpajan nimeltä Kiinalaisen huoneen arvoitus: automaattisen sisällönkuvailun arviointi jatkuu. Työpaja oli jatkoa vuosien 2017 ja 2019 Kirjastoverkkopäivien työpajoille, joissa niissäkin pureuduttiin automaattisen sisällönkuvailun laatuun ja Annifiin, joka on automaattisen sisällönkuvailun työkalu.
Työpajan nimi juonsi juurensa filosofi John Searlen vuonna 1980 esittämästä ajatusleikistä (Searle 1980). Oletetaan, että rakennamme huoneen, jonka ovesta voi työntää sisään kiinaksi kirjoitettuja viestilappuja. Huoneen sisällä viestejä vastaanottamassa on kiinaa osaamaton henkilö, joka voi myös työntää ulos kiinaksi kirjoittamiaan vastauksia. Hänellä on käytössään paksu ohjekirja, joka sisältää hänen ymmärtämällään kielellä (esimerkiksi englanniksi) sääntöjä siihen, miten eri merkkejä sisältäviin viesteihin tulisi vastata. Huoneen ulkopuolella on kiinaa osaava henkilö, joka esittää viestilapuin kysymyksiä – ja saa niihin uskottavia kiinankielisiä vastauksia, jotka huoneessa istuva henkilö on ohjekirjaa noudattamalla tuottanut.
Voidaanko sanoa, että kiinalainen huone ymmärtää kiinaa, vaikka huoneen sisällä oleva henkilö selvästikään ei ymmärrä? Kysymys kytkeytyy näkemykseen tekoälyn rajoista, sillä ohjekirjaa orjallisesti noudattavan henkilön tilalla voisi yhtä hyvin olla algoritmia suorittava tietokoneohjelma; jos kiinalaisen huoneen katsotaan ymmärtävän kiinaa, sama pätee myös sääntöpohjaiseen tekoälyyn. Searlen näkemys oli, että mekaanisiin sääntöihin perustuva tietokoneohjelma ei voi saavuttaa todellista ymmärrystä, ja tätä hän yritti havainnollistaa kiinalaisen huoneen esimerkillä. Samankaltainen tilanne syntyy, kun sisällönkuvailua tuotetaan tekoälyn avulla, esimerkiksi Annifilla. Algoritmit kuvailun tuottamiseen voivat olla vaikka kuinka monimutkaisia, mutta pohjimmiltaan ne koostuvat vain joukosta sääntöjä, joita suoritetaan mekaanisesti, ilman todellista ymmärrystä dokumentin sisällöstä. On kuitenkin ainakin periaatteessa mahdollista, että tekoäly toimii niin hyvin, ettei sen tuottamaa sisällönkuvailua pysty laadullisesti erottamaan ihmisen laatimasta. Tätä arviointia teimme työpajassa.
Olemme kirjoittaneet Annifista sekä vuoden 2019 työpajasta Tietolinjaan (Lehtinen, Suominen & Inkinen 2019). Annifista voi lukea lisää myös siitä kirjoitetuista artikkeleista (Suominen 2019; Suominen, Lehtinen & Inkinen 2022), Finton asiakaswikistä (Finto 2021) tai Annifin verkkosivuilta (Annif 2021). Kokemuksista Annifin käytöstä Theseus-julkaisuarkistossa on kirjoitettu myös Kreodi-lehdessä (Tolonen 2021).
Vuoden 2019 työpajan jälkeen Annif on kehittynyt paljon: olemme muun muassa lisänneet uusia algoritmeja (esimerkiksi MLLM ja neuroverkkopohjainen ensemble-malli) ja keränneet aiempaa kattavampia ja laadukkaampia koulutus- ja arviointiaineistoja. Annifiin perustuva automaattisen sisällönkuvailun verkkopalvelu Finto AI (Finto AI 2021) julkaistiin toukokuussa 2020, mikä merkitsi myös Annifiin pohjautuvan automaattisen sisällönkuvailun siirtymistä tuotantokäyttöön. Olemme matkan varrella käyttäneet pääasiassa numeerisia mittareita, kun olemme vertailleet Annifin tuottamaa sisällönkuvailua ihmisen laatimaan. Työpaja työpaja tarjosi mahdollisuuden arvioida kuvailujen laatua myös suoraan. Työpajan tarkoituksena oli saada laajempi käsitys automaattisen asiasanoittajan Annifin suorituskyvystä ja myös tehdä automaattista sisällönkuvailua sekä sen laatua, vahvuuksia ja rajoitteita tunnetuksi.
Työpaja järjestettiin vuonna 2021 etäyhteyksin (kts. kuva 1), mikä vaati jonkin verran erityisjärjestelyjä vuoden 2019 työpajaan nähden. Kaiken kaikkiaan teknisesti ottaen työpaja sujui mallikkaasti. Osallistujia työpajassa oli 32.

Kuva 1. Työpajan tekniikkahuone. Kuva: Osma Suominen, 2021.
Saimme mukaan videoidun esityksen (Golub 2020) muodossa myös professori Koraljka Golubin ruotsalaisesta Linné-yliopistosta ja hän osallistui lisäksi aktiivisesti keskusteluun työpajan yleisön kanssa. Esitys käsitteli automaattisen sisällönkuvailun laadun arviointia.
Työpajassa esittelimme myös Sisällönkuvailun asiantuntijaryhmän Siskun tekemää Finto AI -palvelun testausta. Testauksen ei ollut tarkoitus olla täysi tieteellinen tutkimus tai käytettävyystutkimus, vaan tarkoitus oli kerätä kokemuksia Finto AI:sta ammattilaiskuvailijan käytössä. Testissä kahdeksan sisällönkuvailun ammattilaista testasi Finto AI:n verkkokäyttöliittymää materiaalilla, jota he työssään käsittelevät. Kyselyn tuloksista voi lukea lisää testiraportista (Lehtinen (toim.) 2020).
Automaattisen sisällönkuvailun laadun arvioinnista
Aineiston määrän kasvamisen myötä kasvaa tarve kuvailutyön automatisoinnille. Automaattisen sisällönkuvailun laadun arvioinnin tärkeys korostuu sitä mukaa, kun automaattisia kuvailutyökaluja otetaan käyttöön. Useimpia automaattisen sisällönkuvailun ratkaisuja testataan vertaamalla niitä johonkin hyvänä pidettyyn lähtökohtaan, esim. ihmisten tuottamiin kuvailuihin. Laadun arvioinnissa korostuvat tällöin tietyt mittaluvut ja metriikat. Golub et. al. (2016) esittelevät artikkelissaan automaattisen sisällönkuvailun laajempana kehikkomallina, joka ottaa huomioon myös sen, kuinka hyvin tutkittu automaattisen kuvailun ratkaisu toimii aiotussa käyttötilanteessaan.
Aineistot ja kuvailujen lähteet
Työpajassa arvioitavia dokumentteja oli 60 kpl. Materiaalina käytimme opinnäytetöitä (gradut, väitöskirjat) sekä sarjajulkaisuja. Aineistot oli kerätty kuudesta eri korkeakoulujen julkaisuarkistosta (JYX, Osuva, Trepo, Lauda, Theseus ja Taju) siten, että jokaisesta julkaisuarkistosta poimittiin 10 kappaletta keskenään samaa aineistotyyppiä edustavaa dokumenttia. Gradut ja sarjajulkaisut olivat suomenkielisiä, väitöskirjat englanninkielisiä.
Jokaisesta dokumentista käytössämme oli kaksi ihmisvoimin laadittua sisällönkuvailua. Aivan aluksi poimimme työpajan käyttöön julkaisuarkistojen omissa metatiedoissa esiintyvät sisällönkuvailut. Tämä vaikutti jonkin verran myös dokumenttien valintaan; läheskään kaikille julkaisuarkistoista löytyville dokumenteille ei ollut määritelty asiasanoja, minkä takia valitsimme vain sellaisia dokumentteja, joille löytyi sisällönkuvailu. Väitöskirjojen ja sarjajulkaisujen sisällönkuvailut poimimme kansallisbibliografia Fennicasta. Graduja ei kuvailla Fennicaan, mutta pyysimme Fennica-kuvailijoita laatimaan myös niille Fennican periaattein tehdyt sisällönkuvailut. Kaikissa sisällönkuvailuissa oli lähtökohtana käyttää Yleisen suomalaisen ontologian (YSO) yleiskäsitteitä sekä YSO-paikkoja. Jätimme kuvailusta pois muun tyyppiset asiasanat kuten henkilöt ja yhteisöt, joita oli käytetty julkaisuarkistojen metatiedoissa ja Fennicassa. Näin eri lähteistä saaduissa kuvailuissa käytetyt asiasanat olivat keskenään samantyyppisiä ja siten helpommin vertailtavissa.
Tuotimme vastaavia kuvailuja myös Annifin eri algoritmeilla. Käytimme uusimpia, syksyn 2021 aikana koulutettuja algoritmeja ja koneoppimismalleja, jotka pian työpajan jälkeen otettiin käyttöön myös Finto AI -palvelussa. Perustason algoritmeja oli käytössä kolme: fastText ja Omikuji Bonsai, jotka oli koulutettu Finnasta poimituilla metatiedoilla, sekä MLLM, joka oli koulutettu kokoelmalla eri lähteistä poimittuja kokotekstidokumentteja, mm. vapaakappaleteoksia, tietokirjojen esittelytekstejä sekä JYX-julkaisuarkiston graduja ja väitöskirjoja. Perusalgoritmien lisäksi käytettiin neuroverkkoon perustuvaa ns. ensemble-mallia (jäljempänä NN-ensemble), joka yhdistelee perusalgoritmien antamia tuloksia ja yltää yleensä parempiin tuloksiin kuin perusalgoritmit yksinään. Koulutusaineiston koostamisessa huolehdittiin siitä, että työpajassa käytetyt dokumentit eivät esiintyneet algoritmeille annetussa aineistossa. Tällä tavoin varmistimme, etteivät algoritmit tuottaneet epärealistisen hyviä sisällönkuvailuja näille dokumenteille.
Kaikille neljälle algoritmille syötettiin dokumenttien kokoteksti. Näin saatiin jokaiselle dokumentille neljä hieman erilaista koneellisesti tuotettua sisällönkuvailua. Gradujen ja väitöskirjojen sisällönkuvailussa kokeiltiin myös pelkästään dokumentin tiivistelmän eli abstraktin käyttämistä NN-ensemble-algoritmin syötteenä; sarjajulkaisuilla ei useinkaan ollut tähän käyttöön soveltuvia tiivistelmiä. Englanninkielisten väitöskirjojen tekstisisältöjä käännettiin englannista suomeksi Chromium-selaimen lisäosaksi asennetulla Google Translate -konekäännösohjelmalla, minkä jälkeen teksti annettiin Annifin suomenkieliselle NN-ensemble-mallille. Ajatuksena oli kokeilla, muuttuuko koneellisen sisällönkuvailun laatu, jos lähteenä käytetään tiivistelmää tai konekäännöksen läpi kulkenutta tekstiä.
| Aineistotyyppi | Julkaisuarkistot | Kuvailujen lähteet |
| suomenkieliset gradut | 10 kpl JYX (Jyväskylän yliopisto)
10 kpl Osuva (Vaasan yliopisto) |
Julkaisuarkiston oma kuvailu; Fennica-kuvailijat; Annif (ml. tiivistelmät) |
| englanninkieliset väitöskirjat | 10 kpl Trepo (Tampereen yliopisto)
10 kpl Lauda (Lapin yliopisto) |
Julkaisuarkiston oma kuvailu; Fennica; Annif (ml. tiivistelmät ja konekäännös) |
| suomenkieliset sarjajulkaisut | 10 kpl Theseus (ammattikorkeakoulut)
10 kpl Taju (Taideyliopisto) |
Julkaisuarkiston oma kuvailu; Fennica; Annif |
Taulukko 1: Työpajassa käytetyt aineistot ja kuvailulähteet.
Työpajan osallistujat ja tehtävät
Työpajaan osallistui 32 henkilöä. Osallistujien sisällönkuvailukokemuksen määrä vaihteli paljon: osalla kokemusta ei ollut lainkaan, toisilla kokemusta oli yli 20 vuotta. Noin puolet osallistujista teki sisällönkuvailua työkseen ainakin osan työajastaan, ja viidellä osallistujalla sisällönkuvailun osuus työtehtävistä oli yli kolmanneksen. Osallistujia pyydettiin arvioimaan kullekin dokumentille annettuja erilaisia kuvailuja, joista ei käynyt ilmi miten ne oli tuotettu ja joiden järjestys oli sekoitettu. Osallistujille esitettiin kolme kuvailua koskevaa väittämää, joita heitä pyydettiin arvioimaan asteikolla 1–5:
- Kattavuus: kuvailu on kattava
- Merkityksellisyys: käytetyt asiasanat ovat sisällön kannalta merkityksellisiä
- Laatu: kuvailu on laadukas
Arvosana 1 oli huonoin (ei lainkaan samaa mieltä) ja 5 paras (täysin samaa mieltä). Osallistujat saivat myös merkitä kuvailuissa käytettyjä asiasanoja poistettavaksi ja antaa vapaamuotoista palautetta kuvailuista. Arvioinnit tehtiin osallistujakohtaisiin Google-taulukoihin (Kansalliskirjasto 2021), ja niissä jokaiselle osallistujille oli annettu 10 dokumenttia, jotka edustivat eri dokumenttityyppejä ja julkaisuarkistoja. Työpajassa tuotettiin 1134 arvioita kuvailuille (keskimäärin 2,7 arviota/kuvailu). Työpajan keston aikana kukin osallistuja ehti käydä läpi keskimäärin 5,2:n dokumentin kuvailut. Raportointiin otettiin mukaan sellaiset kuvailut, joissa oli annettu vähintään yksi arvosana.
Työpaja järjestettiin Zoom-etäyhteyksin. Tehtävän ajan käytössä oli kaksi huonetta. Päähuoneessa näkyvillä oli koko ajan edistymistä seuraava mittaristo (kuva 2). Erilliseen Neuvonta-huoneeseen oli mahdollista tulla kysymään apua häiritsemättä muiden työskentelyä. Kaikkiaan arviointityöhön oli käytettävissä noin 45 minuuttia, minkä jälkeen pidettiin tauko.
Työpajan tulosten analysointi toteutettiin aiempaan tapaan data-analyysiin hyvin soveltuvassa Jupyter Notebook -ympäristössä, ja analysoinnissa käytetiin muun muassa Pandas-ohjelmistokirjastoa. Ensimmäiset alustavat tulokset esiteltiin jo työpajan lopussa. Työpajan lopun englanninkielisissä esityksissä käsiteltiin sekä Siskun Finto AI -testejä että itse työpajan alustavia analyysituloksia. Näistä esityksistä tehty videotallenne on julkaistu Kansalliskirjaston YouTube-kanavalla (Lehtinen, Inkinen & Suominen 2021).
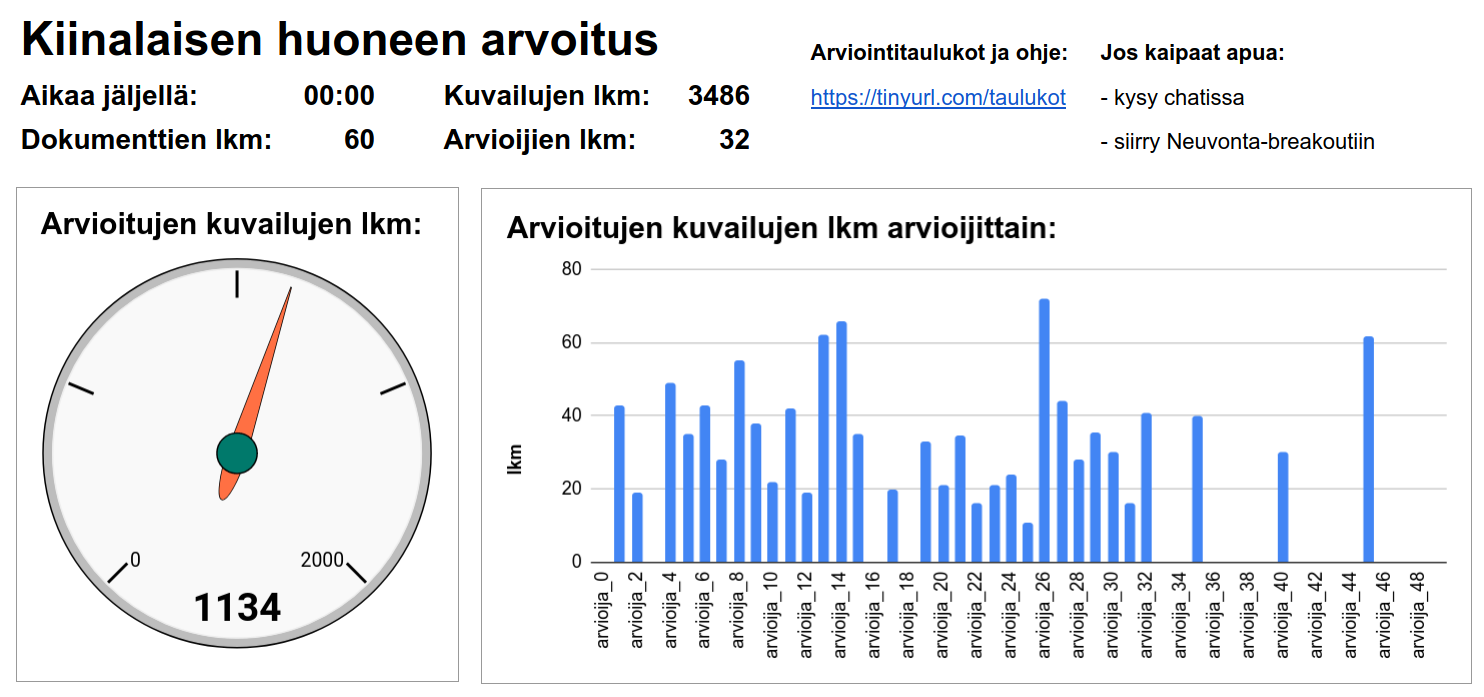
Kuva 2. Työskentelyn etenemistä seurattiin reaaliaikaisesti mittaristonäkymän avulla.
Työpajan tulokset
Yhteenveto eri tavalla tuotettujen sisällönkuvailujen saamista laatuarvioista on esitetty kuvassa 3 (tarkat luvut, kts. liitteen taulukko 2). Kuvasta on kuitenkin jätetty pois tiivistelmien ja konekäännöksen perusteella tuotetut kuvailut, koska näitä menetelmiä ei voitu käyttää kaikille aineistoille. Kullakin kuvailulähteellä on keskimäärin 161 arviota. Parhaat arviointipisteet kaikilla kolmella mittarilla (kattavuus, merkityksellisyys, laatu) annettiin Fennican sisällönkuvailuille (sininen) – siis joko Fennicasta poimituille (väitöskirjat ja sarjajulkaisut) tai Fennica-kuvailijoiden työpajaa varten laatimille kuvailuille (gradut). Myös poistojen osuus oli Fennica-kuvailuissa pienin, noin 6 %. Arkistojen omat kuvailut (violetti) saivat myös melko hyvät arviot, mutta olivat kuitenkin laadultaan keskimäärin selvästi Fennicaa heikompia ja poistojen osuus (n. 8 %) oli suurempi.
Annifin tuottamista kuvailuista odotetusti parhaat arviointipisteet sai NN-ensemble (tummin oranssi). Sen tuottamat kuvailut arvioitiin lähes Fennican veroisiksi ja selvästi arkistojen omia kuvailuja paremmiksi; poistojen osuus tosin oli aavistuksen isompi kuin arkistojen omissa kuvailuissa. Annifin perusalgoritmien (vaaleammat oranssit) tuottamat kuvailut olivat laadultaan selvästi NN-ensembleä heikompia ja poistojen osuudet paljon isompia, 13–20 %.
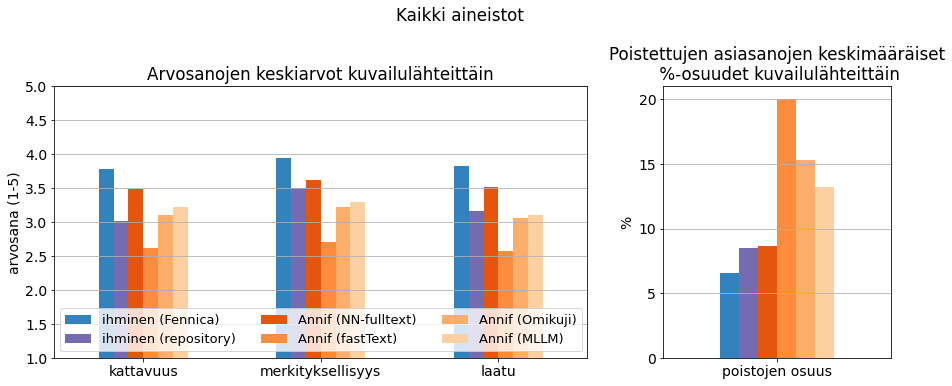
Kuva 3. Yhteenveto työpajassa tuotetuista laatuarvioista ja poistojen osuuksista jaoteltuna kuvailulähteen mukaan.
Gradut
Työpajassa käytetyistä suomenkielisistä graduista 10 oli peräisin Jyväskylän yliopiston JYX-arkistosta ja toiset 10 Vaasan yliopiston Osuva-arkistosta. Kuvassa 4 (kts. myös liitteen taulukko 3) näkyy gradujen sisällönkuvailulle annettuja arviointipisteitä ja poistojen osuuksia sisällönkuvailun lähteen mukaan jaoteltuna. Kullakin kuvailulähteellä on keskimäärin 58 arviota. Fennica-kuvailijoiden laatimille kuvailuille annetut arviot (sininen palkki) arvioitiin kaikilla kolmella laatumittarilla parhaiksi, vaikka poistojen osuus oli melko suuri, hieman yli 10 %. Arkistojen omat kuvailut (violetti) sen sijaan arvioitiin lähes kaikilla mittareilla heikoimmiksi; ainostaan merkityksellisyydessä jotkin Annifin perusalgoritmit jäivät hieman alemmille pisteille.
Annifin tuottamista sisällönkuvailuista parhaiten pärjäsi tiivistelmän perusteella NN-ensemblellä tuotetut sisällönkuvailut (vihreä). Ne arvioitiin lähes yhtä hyviksi kuin Fennica-kuvailijoiden tuottamat. Poistojen osuus tiivistelmästä tuotetuissa sisällönkuvailuissa oli myös selvästi pienin, noin 5 %. Vähäinen poistojen osuus voi johtua siitä, että tiivistelmästä on jätetty pois kaikki epäolennainen. Kokoteksteistä automaattisesti tuotetuissa sisällönkuvailuissa on isompi riski sille, että algoritmit tarttuvat johonkin epäolennaiseen tekstissä mainittuun asiaan ja harhautuvat sen vuoksi. NN-ensemblellä kokotekstistä tuotettu kuvailu (tummin oranssi) oli jonkin verran heikompi kuin tiivistelmän kautta tuotettu ja poistojen osuus sillä oli isompi, noin 7 %.
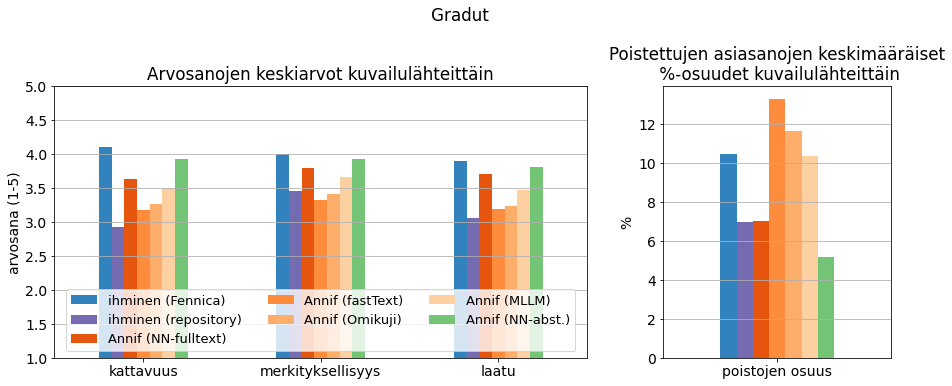
Kuva 4. Gradujen sisällönkuvailujen saamat laatuarviot ja poistojen osuudet.
Kuvan 5 esimerkkidokumentti on Jyväskylän yliopiston JYX-arkistosta ja käsittelee hiilidioksidipäästöjä. Tämän dokumentin kuvailut on arvioinut 4 henkilöä. Arkiston oma sisällönkuvailu (violetti, oikealla kolmantena) on suppea ja koostuu vain neljästä asiasanasta; se sai arvioinnissa kaikkein huonoimmat arviointipisteet (keskiarvo kattavuus-, merkityksellisyys- ja laatupisteistä). Parhaat pisteet sai Fennica-kuvailijoiden tuottama sisällönkuvailu (sininen, oikealla alimpana), mutta lähes samoihin pisteisiin ylti tiivistelmän perusteella NN-ensemblellä tehty sisällönkuvailu (vihreä, oikealla ylimpänä). Muiden, kokotekstistä Annifilla tuotettujen sisällönkuvailujen, saamat pisteet olivat jonkin verran heikompia.
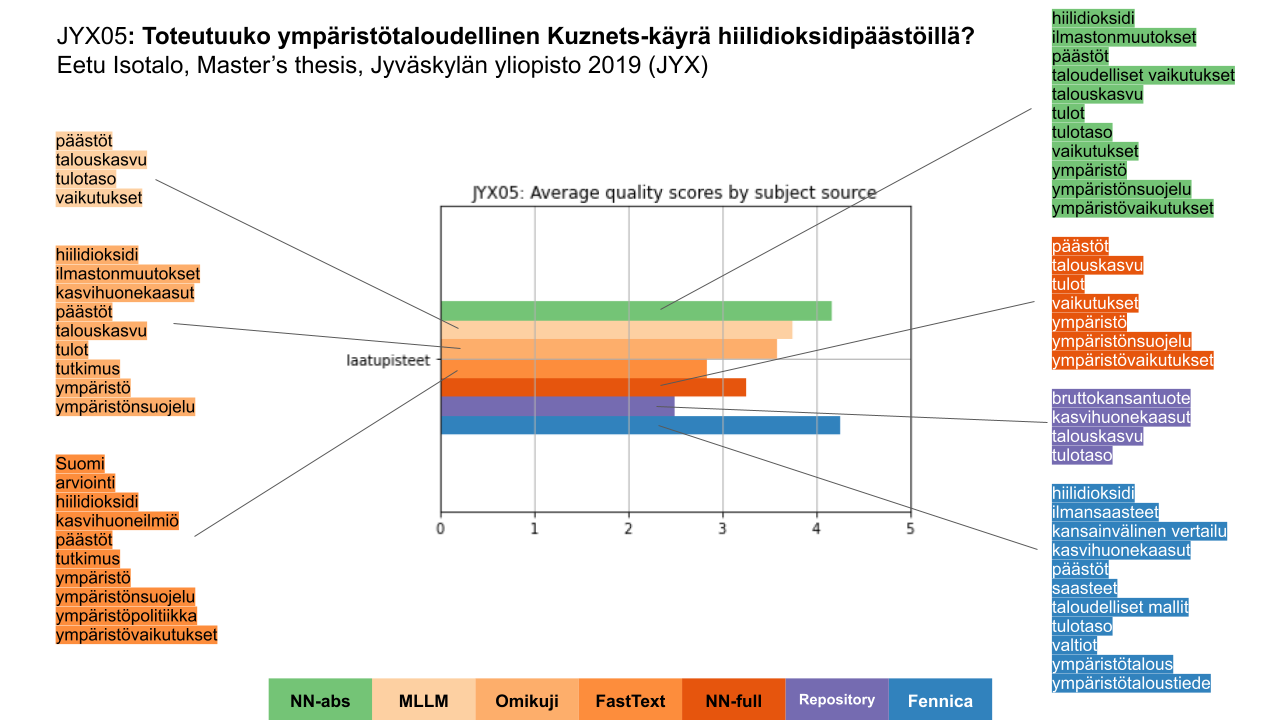
Kuva 5. Esimerkki JYXin gradusta, sille tuotetut kuvailut sekä niiden saamat arviointipisteet.
Kuvan 6 esimerkkidokumentti on huostaanoton lopettamista käsittelevä gradu, joka on julkaistu Vaasan yliopiston Osuva-arkistossa. Kuvailut on arvioinut 2 henkilöä. Julkaisuarkiston oma sisällönkuvailu (violetti, oikeanpuoleisimmassa sarakkeessa alimpana) on varsin suppea ja koostuu vain neljästä asiasanasta. Fennica-kuvailijoiden laatima sisällönkuvailu (sininen, oikealla alimpana) on huomattavasti laajempi. Kumpikin on saanut arvioinnissa keskinkertaiset arviointipisteet. Tämän dokumentin kohdalla poikkeuksellista oli, että kaikki Annifin tuottamat kuvailut (punaiset sävyt) arvioitiin paremmiksi kuin ihmisten laatimat; kokotekstin perusteella NN-ensemblen (tummanpunainen, oikeanpuolimmaisessa sarakkeessa keskellä) tuottama kuvailu sai lähes maksimipisteet. Myös tiivistelmän perusteella tuotettu sisällönkuvailu (vihreä, oikealla ylimpänä) arvioitiin erittäin hyväksi.
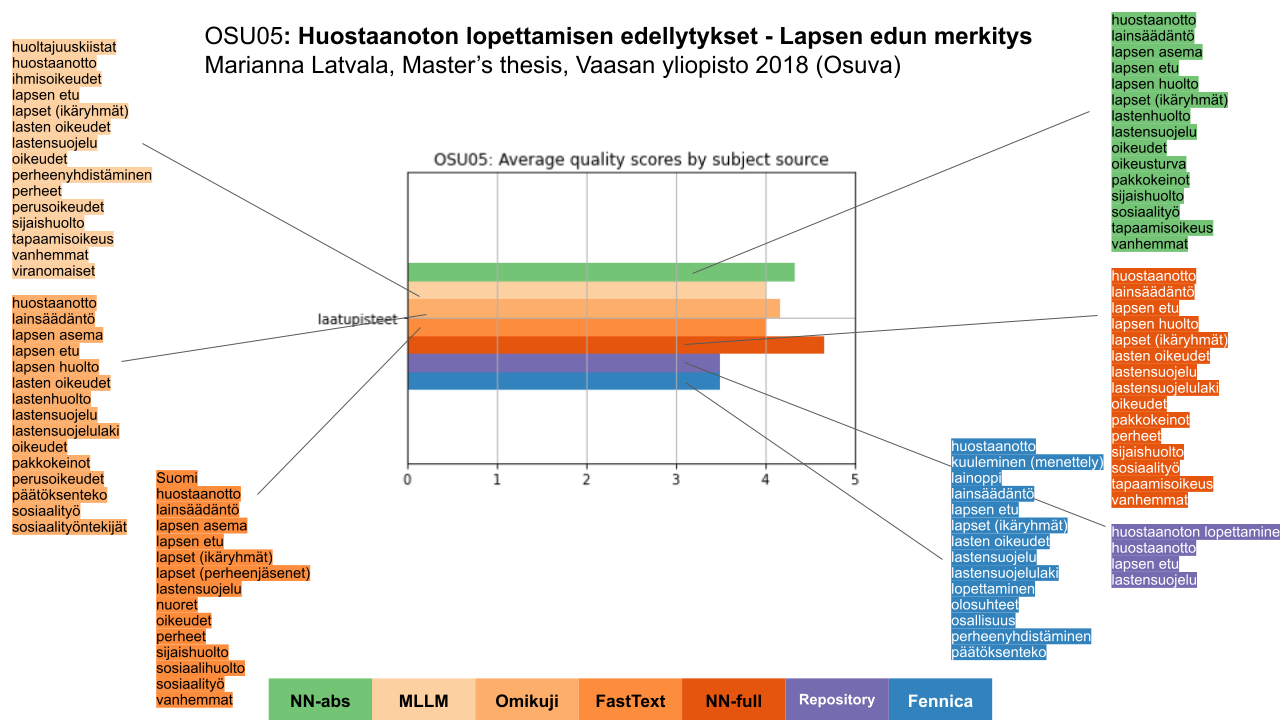
Kuva 6. Esimerkki Osuvan gradusta, sille tuotetut kuvailut sekä niiden saamat arviointipisteet.
Väitöskirjat
Työpajassa käytetyistä englanninkielisistä väitöskirjoista 10 oli peräisin Tampereen yliopiston Trepo-arkistosta ja toiset 10 Lapin yliopiston Lauda-arkistosta. Kuvassa 7 näkyy väitöskirjojen sisällönkuvailulle annettuja arviointipisteitä ja poistojen osuuksia sisällönkuvailun lähteen mukaan jaoteltuna (kts. myös liitteen taulukko 4). Kullakin kuvailulähteellä on keskimäärin 53 arviota. Fennicasta poimitut kuvailut (sininen) arvioitiin merkityksen ja laadun osalta parhaiksi ja kattavuuden osalta lähes parhaaksi; poistojen osuus oli pieni, noin 5 %. Arkistojen omat kuvailut (violetti) arvioitiin selvästi heikommiksi kaikilla mittareilla ja poistojen osuus niissä oli noin 13 %.
Annifin tuottamista kuvailuista parhaaksi arvioitiin NN-ensemble-algoritmilla kokotekstistä tuotetut kuvailut (tummin oranssi), jotka ylsivät lähes samoihin arviointipisteisiin kuin Fennica-kuvailut. Poistojen osuus niissä oli kuitenkin isompi, noin 10 %. Myös tiivistelmästä NN-ensemblellä tuotetut kuvailut (tummempi vihreä) arvioitiin varsin hyviksi ja poistojen osuus oli niissä jonkin verran pienempi, noin 8 %. Perusalgoritmeista MLLM (vaalein oranssi) pärjäsi varsin hyvin, muut selvästi heikommin.
Väitöskirjojen kuvailuaineistossa mukana oli myös konekäännöksen kautta Annifin suomenkielisellä NN-ensemble-algoritmilla tuotettuja kuvailuja (vaaleampi vihreä). Arviointipisteiltään nämä kuvailut jäivät algoritmeista toiseksi heikoimmaksi ja poistojen osuus oli valtava, noin 27 %. Konekäännösteknologian käyttö automaattisen sisällönkuvailun prosessissa ei tämän perusteella vaikuttaisi kovin lupaavalta.
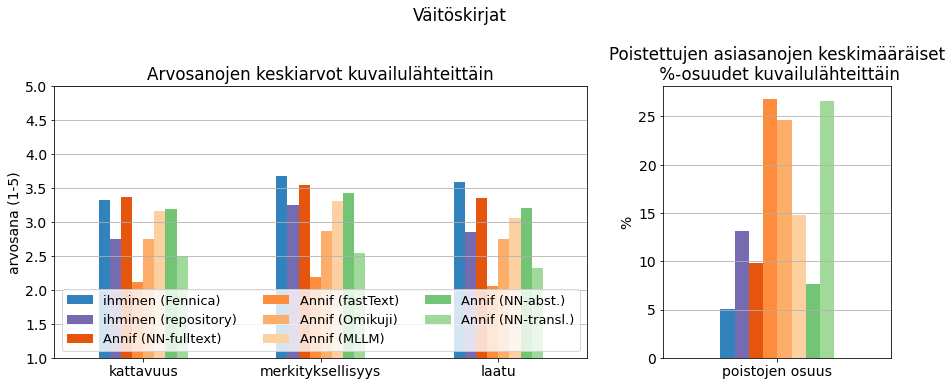
Kuva 7. Väitöskirjojen sisällönkuvailujen saamat arviointipisteet ja poistojen osuudet.
Kuvan 8 esimerkkidokumentti on vuorovaikutteisen teknologian alan väitöskirja Tampereen yliopiston Trepo-arkistosta. Kuvailut on arvioinut 3 henkilöä. Tämän dokumentin kohdalla parhaat arviot sai arkiston oma, neljästä asiasanasta koostuva kuvailu (violetti, oikealla keskellä) ja toiseksi parhaat Fennicasta poimittu kuvailu (sininen, oikealla alhaalla). NN-ensemblen kokotekstin perusteella tuottama kuvailu (tumma oranssi, oikealla ylhäällä) pärjäsi myös hyvin; muut Annifin perusalgoritmit yksitellen eivät niinkään. Tiivistelmästä NN-ensemblellä tuotetut kuvailut yleisesti toimivat melko hyvin väitöskirja-aineistolla, mutta tästä väitöskirjasta näin tuotettu kuvailu (tummempi vihreä, vasemmalla toisena) oli selvästi puutteellinen, ja se sai heikoimmat mahdolliset arviointipisteet kaikilla mittareilla kaikilta arvioijilta. Konekäännöksen perusteella tuotettu kuvailu (vaaleampi vihreä, vasemmalla ylimpänä) oli odotetusti myös heikkolaatuinen.
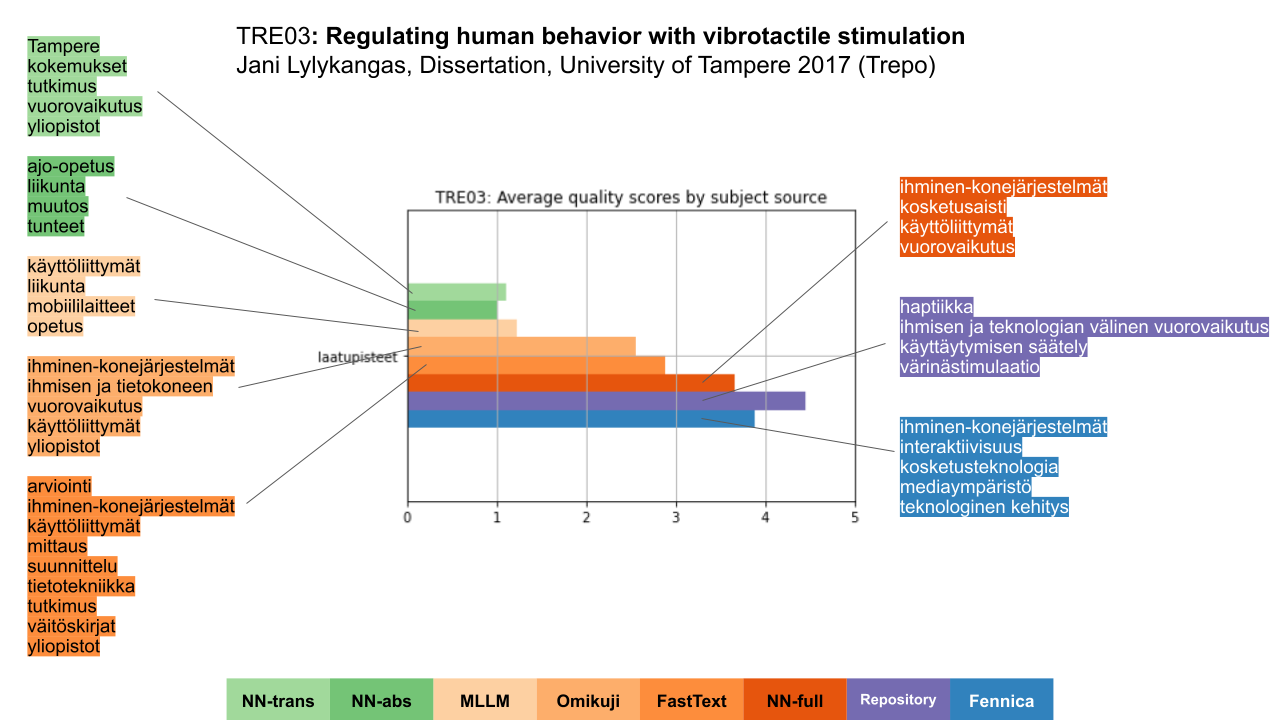
Kuva 8. Esimerkki Trepo-arkiston väitöskirjasta, sille tuotetut kuvailut sekä niiden saamat arviointipisteet
Kuvan 9 esimerkkidokumentti on Lapin yliopiston Lauda-arkistosta poimittu yhteiskuntatieteen alan väitöskirja, joka käsittelee vanhusten kaltoinkohtelua Sambiassa. Kuvailuja on arvioinut 4 henkilöä. Tämän dokumentin kohdalla parhaat arviot sai Fennicasta poimittu kuvailu (sininen, oikealla alimpana). Lähes samoihin pisteisiin ylsi yllättäen konekäännöksen pohjalta NN-ensemblellä tehty kuvailu (vaaleampi vihreä, oikealla ylhäällä), vaikka tämä lähestymistapa yleisesti toimi varsin heikosti. Arkiston oma kuvailu (violetti, oikealla alhaalla) arvioitiin keskinkertaiseksi; se myös sisältää YSOon kuulumattomia ja jopa väärin kirjoitettuja asiasanoja kuten “Zambian maaseutu ja kaupungit” (po. Sambian) ja “vanhusten kaltoinkohtelu”. NN-ensemblellä kokotekstistä tuotettu kuvailu (tumma oranssi, oikealla kolmantena) sai tätä hieman paremmat arviointipisteet, mutta siitä jäi puuttumaan paikkaa ilmaiseva asiasana Sambia, vaikka tämä oli aivan keskeinen aihe väitöskirjassa. Muut Annifilla tuotetut sisällönkuvailut olivat nekin monelta osin puutteellisia, mutta fastText (toiseksi tummin oranssi) oli niistä selkeästi huonoin.
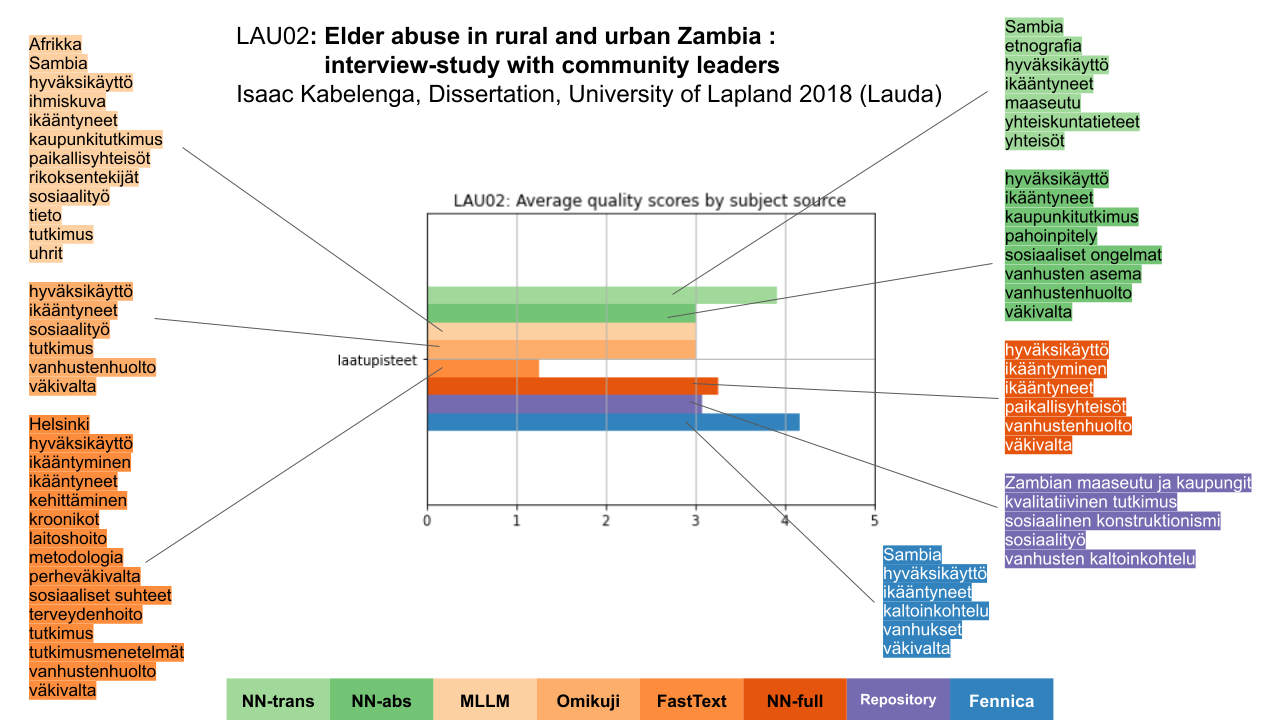
Kuva 9. Esimerkki Lauda-arkiston väitöskirjasta, sille tuotetut kuvailut sekä niiden saamat arviointipisteet.
Sarjajulkaisut
Työpajassa käytetyistä sarjajulkaisuista 10 oli peräisin ammattikorkeakoulujen yhteisestä Theseus-arkistosta ja toiset 10 Taideyliopiston Taju-arkistosta. Sarjajulkaisut olivat aineistoista monimuotoisimpia, koska korkeakoulut tuottavat hyvin monenlaisia julkaisuja. Kuvassa 10 näkyy sarjajulkaisujen sisällönkuvailulle annettuja arviointipisteitä ja poistojen osuuksia sisällönkuvailun lähteen mukaan jaoteltuna (tarkemmat luvut liitteen taulukossa 5). Kullakin kuvailulähteellä on keskimäärin 50 arviota. Fennicasta poimitut kuvailut (sininen) arvioitiin kaikilla laatumittareilla parhaiksi ja poistojen osuus oli erittäin pieni, noin 4 %. Arkistojen omat kuvailut (violetti) arvioitiin jonkin verran Fennica-kuvailuja heikommiksi kaikilla mittareilla ja poistojen osuus niissä oli noin 5 %.
Annifin tuottamista kuvailuista parhaaksi arvioitiin jälleen NN-ensemble-algoritmilla kokotekstistä tuotetut kuvailut (tummin oranssi). Ne ylsivät lähes samoihin arviointipisteisiin kuin arkiston omat kuvailut; kattavuuden osalta jopa hieman yli. Poistojen osuus niissä oli selvästi isompi, noin 9 %. Perusalgoritmeista Omikuji (toiseksi vaalein oranssi) pärjäsi tällä kertaa varsin hyvin, muut selvästi heikommin. Sarjajulkaisujen kuvailujen vertailussa kaikkien algoritmien tuottamat kuvailut olivat ihmisten laatimia kuvailuja heikompia, toisin kuin graduissa ja väitöskirjoissa, joissa algoritmit usein päihittivät arkiston omat kuvailut.
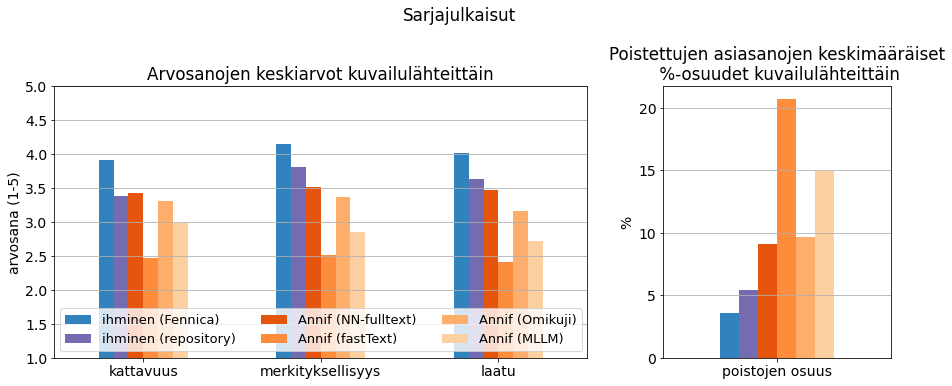
Kuva 10. Sarjajulkaisujen sisällönkuvailujen saamat arviointipisteet ja poistojen osuudet.
Kuvan 11 esimerkkidokumentti on kuvaus biokaasulaitoksiin liittyvästä projektista, jonka Kaakkois-Suomen ammattikorkeakoulu (XAMK) on julkaissut Theseus-arkistossa. Kuvailut on arvioinut 3 henkilöä. Parhaat arviot annettiin Fennica-kuvailulle (sininen, oikealla alhaalla) ja toiseksi parhaat hieman yllättäen MLLM-algoritmin tuottamalle kuvailulle (vaalea oranssi, vasemmalla ylhäällä), vaikka se sisältää ilmeisiä virheitä. Arkiston oma sisällönkuvailu sekä muiden algoritmien tuottavat kuvailut arvioitiin varsin heikkolaatuisiksi.
Algoritmien tuottamissa kuvailuissa silmiinpistävää on se, että kaikki ne sisältävät asiasanan “Kaakkois-Suomi” ja osa myös muita paikkoja kuten Suomi, Mikkeli, Lappeenranta ja jopa Inkerinmaalla sijaitseva Koprina, vaikka dokumentissa näiden paikkojen merkitys on vähäinen tai olematon. Kaakkois-Suomi, Lappeenranta ja Mikkeli mainitaan tekstissä, mutta ne eivät ole aiheen kannalta keskeisiä. Koprina lienee päätynyt vahingossa asiasanaksi tekijän sukunimen (Kopra) kautta.
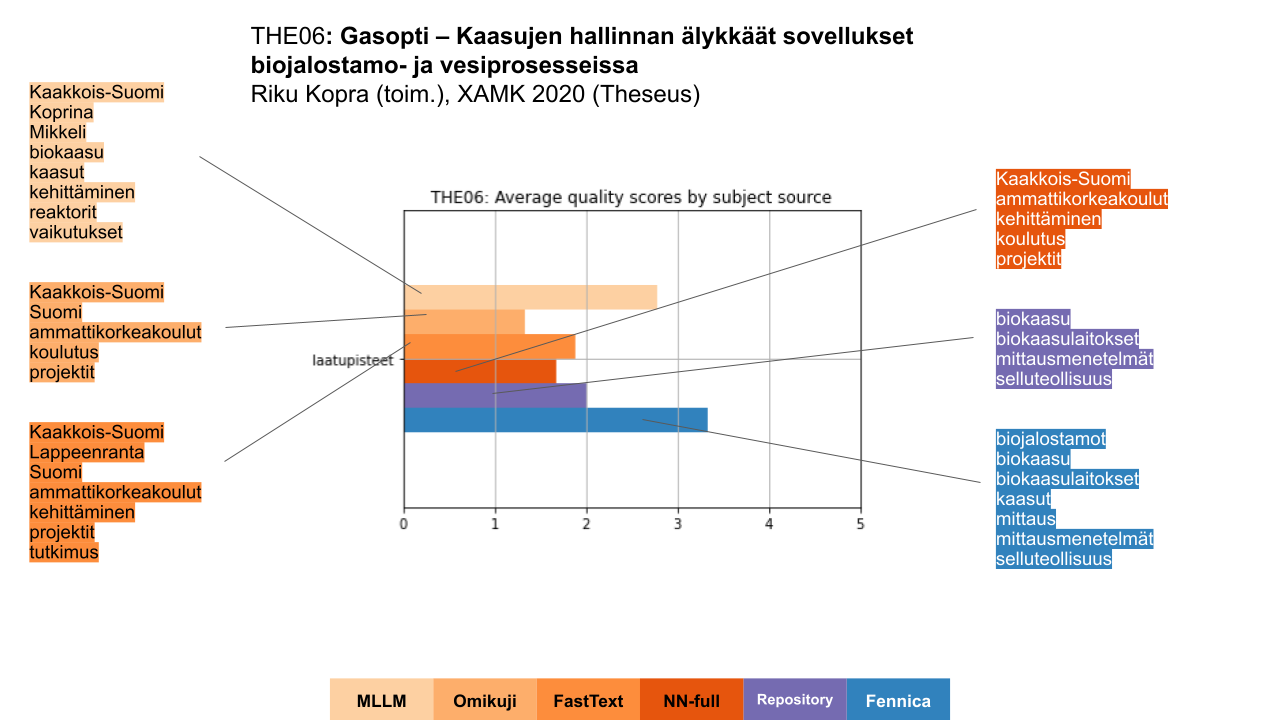
Kuva 11. Esimerkki Theseus-arkiston sarjajulkaisusta, sille tuotetut kuvailut sekä niiden saamat arviointipisteet.
Kuvan 12 esimerkkidokumentti on Taju-arkistossa julkaistu historiikki Teatterikorkeakoulun (nykyisin osa Taideyliopistoa) tanssinopettajien ja teatteriopettajien maisteriohjelmasta. Kuvailuja on arvioinut 2 henkilöä. Tämän dokumentin kohdalla sekä arkiston oma sisällönkuvailu (violetti, oikealla keskellä) että Fennican sisällönkuvailu (sininen, oikealla alhaalla) saivat varsin hyvät arviot, mutta myös NN-ensemblen (tummin oranssi, oikealla ylhäällä) tuottama kuvailu arvioitiin suurin piirtein yhtä hyväksi. Yksittäisten algoritmien tuottamat kuvailut olivat selvästi heikompia. Huomattavaa näissä kuvailuissa on, että molemmat ihmiskuvailut sisältävät historianäkökulman (asiasanat ”historia” ja ”historiikit”), kun taas mikään algoritmi ei historiaan viittaavia asiasanoja ehdottanut.
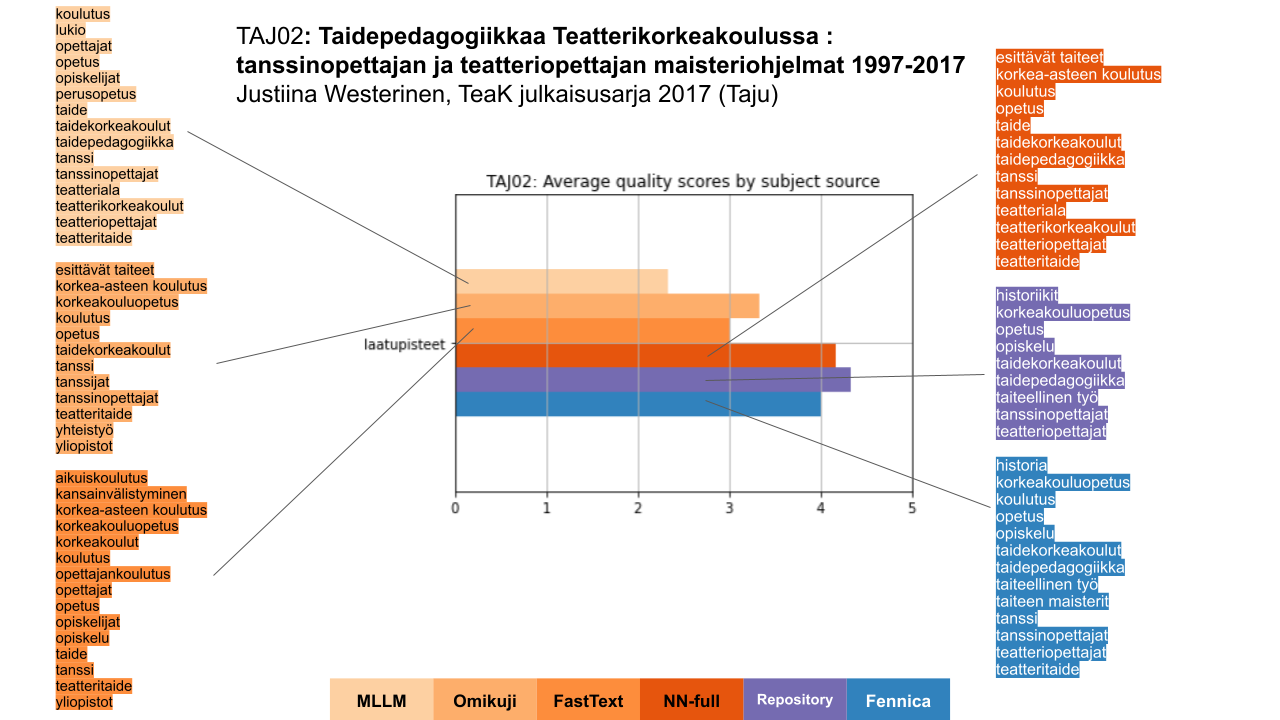
Kuva 12. Esimerkki Taju-arkiston sarjajulkaisusta, sille tuotetut kuvailut sekä niiden saamat arviointipisteet.
Annifin suoriutuminen verrattuna vuoden 2019 työpajaan
Käytimme tässä arvioinnissa jo vuoden 2019 työpajassa käytettyä, Jyväskylän yliopiston JYX-julkaisuarkistosta haettua gradumateriaalia uudelleen. Viime työpajaan verrattuna Annif on suoriutunut suunnilleen samantasoisesti (kuva 13, tarkemmat luvut liitteen taulukossa 6). Ammattimainen ihmiskuvailija saa algoritmeja paremmat pisteet kautta linjan.
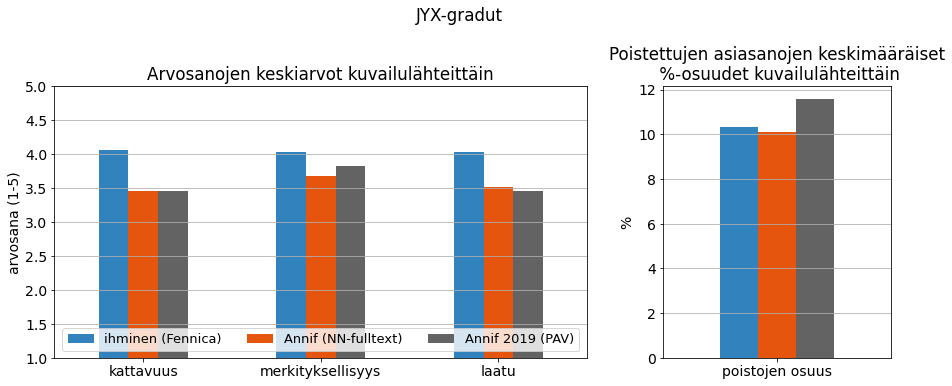
Kuva 13. Vertailu vuosien 2019 ja 2021 työpajojen laatuarvioista JYX-gradujen sisällönkuvailuille.
Poistettujen eli arvioijien virheellisiksi tai turhiksi katsomien asiasanojen määrä on Annifin kohdalla laskenut lähemmäs ihmiskuvailijoiden tasoa. Mielenkiintoista on kuitenkin, ettei Annifin suorituskyky kuvailun kattavuudelle, merkityksellisyydelle ja laadulle annetuilla arvosanoilla mitattuna ole parantunut siinä suhteessa kuin esim. koneellisesti laskettavien metriikoiden (tai hylättyjen asiasanojen määrän) perusteella olisi ehkä voinut olettaa. Toki vastaajia on ollut vähän ja laatuarvosanojen kategoriat tulkinnanvaraisia sekä ehkä karkeitakin mittareita.
Tulosten analyysi
Seuraavassa käymme läpi työpajan saamaa palautetta ja pohdimme sen toteutusta sekä käymme läpi sen herättämiä ajatuksia. Ensimmäinen huomionarvoinen seikka on, että työpajassa oli turhan vähän osallistujia suhteessa aineiston määrään. Tähän vaikutti osaltaan se, että Kirjastoverkkopäivillä oli useita rinnakkaisia työpajoja, jotka myös kiinnostivat monia. Arvioita saatiin siis melko vähän yksittäistä kuvailua kohden. Tämä vaikuttaa tulosten tulkintaan. Toisekseen suuri aineistomäärä aiheutti osallistujille aikapaineen tuntua, mikä näkyi myös siinä, että aikaa itse tehtävälle koettiin olevan liian vähän. Lisäksi aikaa keskustelulle työpajan päätteeksi olisi voinut olla enemmän. Työpaja kuitenkin koettiin mielenkiintoiseksi.
Työpaja järjestettiin epävarman koronatilanteen vuoksi etäyhteyksin, mikä vaati huolellisia ennakkojärjestelyjä ja lisäsi teknisten ongelmien mahdollisuutta. Suuremmilta teknisiltä ongelmilta kuitenkin vältyttiin. Työpajan neuvontahuoneen käytöstä saimme jopa positiivista palautetta. Annif-työpajoissa on perinteisesti jaettu palkinto ansiokkaimmalle osallistujalle, mutta tällä kertaa palkinto jäi jakamatta, sillä se olisi ollut etätyöskentelyssä hankalaa.
Aineistoa oli käytössämme hieman enemmän kuin vuoden 2019 työpajassa, ja aineisto oli myös muodoltaan ja sisällöltään tasalaatuisempaa, koska kaikki dokumentit olivat peräisin korkeakoulujen julkaisuarkistoista. Painettujen aineistojen käyttö ei olisi ollut kovin helppoa etätyöpajassa. Todennäköisesti aineiston tasalaatuisuus aiheutti sen, että laatuvertailun tulokset eri aineistotyypeillä olivat hyvin samansuuntaisia, vaikka pieniä erojakin syntyi. Sekä aineistot että osallistujat olivat eri kuin vuoden 2019 työpajassa ja arviointiin käytetyssä lomakepohjassa oli pieniä eroja, minkä takia tämän vuoden tulokset eivät ole täysin vertailukelpoisia aiempien kanssa.
Työpajan tuloksista vähiten yllätti se, että Fennicasta poimitut ja Fennica-kuvailijoiden laatimat sisällönkuvailut saivat kautta linjan parhaita arvosanoja. Ammattilaisten tuottama sisällönkuvailu on erittäin hyvälaatuista, algoritmit eivät yllä yhtä hyvään laatuun.
Julkaisuarkistojen oma sisällönkuvailu eli asiasanoitus oli sen sijaan laadultaan vaihtelevampaa ja käytännöt kirjavampia. Esimerkiksi asiasanoja ei välttämättä ollut poimittu YSOsta tai sen edeltäjästä YSAsta eli Yleisestä suomalaisesta asiasanastosta. Theseus- ja Taju-arkistoista poimittujen sarjajulkaisujen sisällönkuvailu oli varsin hyvälaatuista, mutta gradujen ja väitöskirjojen sisällönkuvailut arvioitiin laadultaan selkeästi Fennicaa heikommiksi – jopa niin, että monissa tapauksissa Annifin parhaiden algoritmien tuottama sisällönkuvailu ylsi keskimäärin niitä jonkin verran parempiin arviointipisteisiin, lähelle Fennican tasoa. Yksittäisten dokumenttien kohdalla laatuvaihtelut sekä arkiston omassa että algoritmien tuottamassa sisällönkuvailussa olivat kuitenkin isoja.
Annifin algoritmeista selvästi parhaita tuloksia antoi odotetusti NN-ensemble, joka yhdistelee perusalgoritmien tuloksia ja paikkailee siten niiden puutteita ja virheitä. Vuoden 2019 työpajassa vastaavassa roolissa oli samankaltainen PAV-ensemble, joka sekin pärjäsi algoritmeista parhaiten. Mukana vertailussa oli tällä kertaa sekä kokotekstin että pelkän tiivistelmän perusteella NN-ensemblellä tuotettuja asiasanoja. Gradujen ryhmässä tiivistelmistä tuotetut asiasanat saivat parhaat arviointipisteet; väitöskirjojen kohdalla kokoteksti toimi paremmin. Sarjajulkaisuilla ei pääsääntöisesti ollut tiivistelmiä, joten menetelmää ei voinut soveltaa niihin. Tulosten perusteella vaikuttaa siltä, että pelkän tiivistelmätekstin käyttö on automaattisen sisällönkuvailun sovelluksissa varteenotettava vaihtoehto kokotekstin käytölle silloin, kun tiivistelmä on helposti saatavilla.
Mukana vertailussa oli myös konekäännöksen avulla englannista suomeen käännettyjä väitöskirjatekstejä. Konekäännösteknologia mahdollistaisi automaattisen sisällönkuvailun hyödyntämisen myös sellaisille kielille, joille ei ole olemassa sopivia koulutusaineistoja, algoritmeja tai malleja. Tulokset eivät valitettavasti olleet kovin rohkaisevia. Konekäännetystä tekstistä NN-ensemblellä tuotetut asiasanat saivat erittäin heikkoja arviointipisteitä. On toki mahdollista, että jokin toinen käännösmenetelmä tai kielipari olisi toiminut paremmin – suomen kieli kun on tunnetusti haastava käännösohjelmille.
Menetelmien saamien arviointipisteiden keskiarvot kätkevät sen, että sekä ihmisten laatimissa että algoritmien tuottamissa kuvailuissa on paljon laatuvaihtelua ja yleisesti hyväkin algoritmi voi toisinaan tuottaa erittäin huonoja sisällönkuvailuja tai päinvastoin. Tämän ilmiön tarkempi ymmärtäminen voisi auttaa kehittämään automaattista sisällönkuvailua entistä paremmaksi. Yhteistyökumppanimme, Saksan taloustieteen instituutti ZBW onkin kehittänyt menetelmiä (Toepfer & Seifert 2018) ja työkalua (Bartz & Fürneisen 2021), joilla pyritään arvioimaan automaattisesti tuotetun sisällönkuvailun laatua. Automaattisesti laskettavan laatuarvion perusteella voidaan esimerkiksi vaikeat dokumentit ohjata asiantuntijoiden kuvailtavaksi ja helpompien osalta hyväksyä automaattisesti tuotettu sisällönkuvailu sellaisenaan.
Järjestämme automaattiseen kuvailuun keskittyviä työpajoja jatkossakin. Kahden vuoden välein järjestettävät Kirjastoverkkopäivät kerää yhteen laajan joukon aiheesta kiinnostuneita asiantuntijoita, joten työpajat sopivat tähän tapahtumaan hyvin. Vuoden 2021 työpaja oli tällä kertaa hyvin saman tyyppinen kuin vuoden 2019 työpaja, ja pystyimme käyttämään uudelleen monia jo edellistä työpajaa varten kehitettyjä arviointi- ja analyysimenetelmiä. Kenties ensi kerralle keksimme kuitenkin hieman toisenlaisen näkökulman automaattisen kuvailun laatuun. Tapaamisiin Kirjastoverkkopäivillä 2023!
Lopuksi – kiitos!
Haluamme vielä kiittää kaikkia osallistujia, Kirjastoverkkopäivien järjestäjiä sekä professori Koraljka Golubia työpajan mahdollistamisesta. Kiitokset myös työpajan materiaalin tuottamisessa auttaneille, erityisesti Fennica-kuvailijoille, jotka laativat gradujen sisällönkuvailuja työpajaa varten.
Lähteet
Annif (2021). Annif – tool for automated subject indexing. Haettu 9.12.2021 osoitteesta https://annif.org/
Bartz, C. & Fürneisen, M. (2021). Qualle (a framework to predict the quality of a multi-label classification result). GitHub-säilö. Haettu 9.12.2021 osoitteesta https://github.com/zbw/qualle
Finto (2021). Annif ja automaattinen kuvailu. Haettu 9.12.2021 osoitteesta https://www.kiwi.fi/x/F4T6Bg
Finto AI (2021). Finto AI. Haettu 9.12.2021 osoitteesta https://ai.finto.fi/
Golub, K., Dagobert, S., Buchanan, G., Tudhope, D., Lykke, M., & Hiom, D. (2016). A framework for evaluating automatic indexing or classification in the context of retrieval. Journal of the Association for Information Science and Technology, 67(1), 3–16. https://doi.org/10.1002/asi.23600
Golub, K. (2020). Evaluation of automatic subject indexing [Videotallenne]. YouTube. Haettu 9.12.2021 osoitteesta https://youtu.be/L4H1R8N3yrw?t=1420
Kansalliskirjasto (2021). Arvioijakohtaiset taulukot. Google Drive-kansio. Haettu 9.12.2021 osoitteesta https://tinyurl.com/taulukot
Lehtinen, M. (toim.), Anttila, M., Forsén, M. Fröjdholm, T., Hilander, L., Hintikka, O., Lindfors, I.,Tiainen, K., & Turunen, T. (2021). Sisällönkuvailun ammattilaisten kokemuksia Finto AI:n käytöstä. https://urn.fi/URN:ISBN:978-951-51-7816-9
Lehtinen, M., Inkinen, J. & Suominen, O. (2019). Aaveita koneessa: Automaattisen sisällönkuvailun arviointia Kirjastoverkkopäivillä 2019. Tietolinja, 2019(2). http://urn.fi/URN:NBN:fi-fe2019120445612
Lehtinen, M., Inkinen, J. & Suominen, O. (2021). TP4: Kiinalaisen huoneen arvoitus: automaattisen sisällönkuvailun arviointi jatkuu (ENG) [Videotallenne]. YouTube. Haettu 9.12.2021 osoitteesta https://www.youtube.com/watch?v=HUcj1-hMI_w
Searle, J. (1980). ”Minds, Brains and Programs”, Behavioral and Brain Sciences, 3 (3): 417–457, https://doi.org/10.1017%2FS0140525X00005756. Saatavana myös arkistoitu kopio Internet Archivesta.
Suominen, O. (2019). Annif: DIY automated subject indexing using multiple algorithms. LIBER Quarterly, 29(1), 1–25. DOI: http://doi.org/10.18352/lq.10285
Suominen, O., Lehtinen, M. & Inkinen, J. (2022). Annif and Finto AI: Developing and Implementing Automated Subject Indexing. Italian Journal of Library, Archives, and Information Science (JLIS.it), 13(1). Hyväksytty käsikirjoitus saatavana osoitteessa https://urn.fi/URN:NBN:fi-fe2021080942632
Toepfer, M. & Seifert, C. (2018). Content-based quality estimation for automatic subject indexing of short texts under precision and recall constraints. In Proceedings of the International Conference on Theory and Practice of Digital Libraries. Springer, Cham., DOI: https://doi.org/10.1007/978-3-030-00066-0_1
Tolonen, T. (2021). Annif asiasanoittajana – kokemuksia Theseuksesta. Kreodi, 2021(3). http://urn.fi/URN:NBN:fi-fe2021060634290
Kirjoittajien yhteystiedot
Juho Inkinen, tietojärjestelmäasiantuntija
juho.inkinen [at] helsinki.fi
Mona Lehtinen, tietoasiantuntija
mona.lehtinen [at] helsinki.fi
Osma Suominen, tietojärjestelmäasiantuntija
osma.suominen [at] helsinki.fi
Kaikkien kirjoittajien maapostiosoite on
Kansalliskirjasto, kirjastoverkkopalvelut
PL 15 (Yliopistonkatu 1), 00014 Helsingin yliopisto
Liitteet
| Ihminen (Fennica) | Ihminen (repository) | Annif (NN-fulltext) | Annif (fastText) | Annif (Omikuji) | Annif (MLLM) | |
| Kattavuus | 3,78 | 3,02 | 3,47 | 2,61 | 3,09 | 3,23 |
| Merkityksellisyys | 3,93 | 3,51 | 3,62 | 2,70 | 3,21 | 3,29 |
| Laatu | 3,82 | 3,17 | 3,51 | 2,58 | 3,03 | 3,09 |
| Poistojen osuus (%) | 6,98 | 8,83 | 8,88 | 20,41 | 15,85 | 13,74 |
Taulukko 2. Yhteenveto työpajassa tuotetuista laatuarvioista ja poistojen osuuksista jaoteltuna kuvailulähteen mukaan.
| Ihminen (Fennica) | Ihminen (repository) | Annif (NN-fulltext) | Annif (fastText) | Annif (Omikuji) | Annif (MLLM) | Annif (NN-abst.) | |
| Kattavuus | 4,08 | 2,95 | 3,63 | 3,19 | 3,22 | 3,50 | 3,95 |
| Merkityksellisyys | 3,98 | 3,47 | 3,81 | 3,32 | 3,36 | 3,64 | 3,95 |
| Laatu | 3,88 | 3,07 | 3,72 | 3,20 | 3,19 | 3,45 | 3,82 |
| Poistojen osuus (%) | 11,14 | 7,16 | 7,63 | 13,67 | 12,75 | 11,33 | 5,24 |
Taulukko 3. Gradujen sisällönkuvailujen saamat laatuarviot ja poistojen osuudet.
| Ihminen (Fennica) | Ihminen (repository) | Annif (NN-fulltext) | Annif (fastText) | Annif (Omikuji) | Annif (MLLM) | Annif (NN-abst.) | Annif (NN-transl.) | |
| Kattavuus | 3,33 | 2,77 | 3,36 | 2,10 | 2,77 | 3,17 | 3,19 | 2,53 |
| Merkityksellisyys | 3,69 | 3,26 | 3,55 | 2,17 | 2,89 | 3,33 | 3,42 | 2,57 |
| Laatu | 3,59 | 2,87 | 3,34 | 2,04 | 2,75 | 3,06 | 3,21 | 2,36 |
| Poistojen osuus (%) | 4,96 | 13,70 | 9,75 | 28,21 | 24,61 | 15,30 | 7,69 | 26,10 |
Taulukko 4. Väitöskirjojen sisällönkuvailujen saamat arviointipisteet ja poistojen osuudet.
| Ihminen (Fennica) | ihminen (repository) | Annif (NN-fulltext) | Annif (fastText) | Annif (Omikuji) | Annif (MLLM) | |
| Kattavuus | 3,90 | 3,38 | 3,41 | 2,47 | 3,27 | 2,98 |
| Merkityksellisyys | 4,14 | 3,80 | 3,49 | 2,51 | 3,37 | 2,86 |
| Laatu | 4,00 | 3,62 | 3,45 | 2,41 | 3,14 | 2,73 |
| Poistojen osuus (%) | 4,26 | 5,65 | 9,36 | 20,26 | 10,32 | 14,90 |
Taulukko 5. Sarjajulkaisujen sisällönkuvailujen saamat arviointipisteet ja poistojen osuudet.
| Ihminen (Fennica) | Annif (NN-fulltext) | Annif 2019 (PAV) | |
| Kattavuus | 4,06 | 3,45 | 3,45 |
| Merkityksellisyys | 4,03 | 3,68 | 3,82 |
| Laatu | 4,03 | 3,52 | 3,46 |
| poistojen osuus (%) | 10,33 | 10,08 | 11,58 |
Taulukko 6. Vertailu vuosien 2019 ja 2021 työpajojen laatuarvioista JYX-gradujen sisällönkuvailuille.
Leave a Reply