
Laila Heinemann
Kansalliskirjasto
Tämän sivun pysyvä osoite on http://urn.fi/URN:NBN:fi-fe201012143105
Open Linked Datan tai Linked Open Datan – termiä näkee käytettävän molemmin päin – periaate on valloittanut vauhdilla alaa julkishallinnossa eri puolilla maailmaa. Suomeksi siitä käytetään termejä avoin yhdistetty tieto ja linkitetty avoin data. Jälkimmäinen on sikäli parempi, että se on täsmällisempi – suomenkielen ongelmallinen sana tieto tarkoittaa tässä yhteydessä nimenomaan raakadataa ja yhdistäminen nimenomaan linkkien luomista.
Kyse on julkisin varoin tuotetun datan avaamisesta vapaasti kansalaisosallistujien eli ulkopuolisten sovelluskehittäjien käyttöön. Lähtöajatuksena on, että hyöty on molemminpuolinen. Washington D.C.ssä vuonna 2008 järjestetty ensimmäinen Apps for Democracy -kilpailu tuotti 47 käyttökelpoista julkiseen dataan perustuvaa palvelusovellusta. Kaupungin tietohallinto-osasto laski, että näiden sovellusten tuottaminen perinteisen hankintakäytännön kautta olisi maksanut yli kaksi miljoonaa dollaria ja kestänyt yli kaksi vuotta – nyt se maksoi 50 000 ja siihen meni vain pari kuukautta. Suomessa vastaavanlainen Apps4finland -kilpailu on järjestetty jo kahdesti.
Kansalaisosallistujia Suomessa edustavan Tutkimusparven motto on ”Antakaa se meille raakana, antakaa se meille nyt!” Tämän sloganin on heittänyt alun perin itse Tim Berners-Lee, joka on mies myös semanttisen webin ja itse asiassa koko nykyisenlaisen internetin ideoiden takana. (Jos kaipaatte hengennostatusta tästä aiheesta, katsokaa hänen videoitu esityksensä TEDin sivuilta.)
Peruskäsitteitä
Koska myös tässä asiassa termejä heitellään keskustelussa aika huolimattomasti, on ehkä paikallaan aloittaa täsmällisemmillä määritelmillä:
Avoin data (Open Data) tarkoittaa yksinkertaisesti dataa, joka on vapaasti käytettävissä ja kierrätettävissä avoimella lisenssillä.
Linkitetty data (Linked Data) puolestaan tarkoittaa tietoelementtejä, jotka on linkitetty toisiinsa. Se on seuraava askel internetin loogisessa jatkumossa linkitetyt palvelimet > linkitetyt dokumentit > linkitetyt tiedot.
Avoin linkitetty data (Linked Open Data) tarkoittaa dataa, joka on avattu sellaisessa muodossa, että myös muut järjestelmät pystyvät hyödyntämään sitä. Avointa linkitettyä dataa voidaan laajentaa, kierrättää ja yhdistellä edelleen eri sovelluksissa.
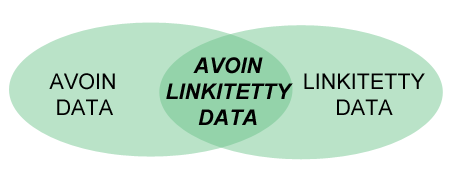
Kuva 1: Käsitteet kaaviona
Vaikka linkitetyssä datassa on kyse teknologiasta, datan avaaminen kenen tahansa käyttöön on (vain) poliittinen päätös. Tähän puoleen on jo otettu kantaa esimerkiksi Valtiotason arkkitehtuurit -hankkeen laatimassa raportissa Julkishallinnon tietoarkkitehtuuri, jossa asia määritellään näin:
Linkitetyn avoimen datan periaatteita ovat:
- Kansalaisilla on oikeus tietoon.
- Kertaalleen tuotettua tietoa ei kannata tuottaa aina uudelleen.
- Tietoja yhdistämällä kaikkien tiedot rikastuvat.
- Asettamalla tieto helposti saataville, voi joku toinen viranomainen, yritys tai kansalainen tehdä datalle hyödyllisen sovelluksen.
- Yhden organisaation pienen edun paikallinen tavoittelu voi olla yhteiskunnan kokonaisedun vastaista.
- Julkisin varoin tuotettu tieto pitää vapauttaa.
Myös EU:n piirissä on herätty uudistamaan julkisen tiedon (Public Sector Information, PSI) saatavuutta koskevaa lainsäädäntöä tähän suuntaan.
Tietoammattilaisia tämä trendi ei voi olla kiinnostamatta, eikä siis ihme, että useita avauksia (sic!) on jo tehty.
Miten data avataan?
Tim Berners-Lee on esittänyt datan avaamiselle viisiportaisen asteikon, johon usein kuulee viitattavan avoimen datan tähtiluokituksena – ja jonka W3C on painanut moniin kampanjatuotteisiinsakin:

Kuva 2: (http://www.cafepress.com/w3c_shop.480759174)
Täsmällisemmin tämä tarkoittaa:
* saatavilla verkossa (missä tahansa formaatissa) avoimella lisenssillä
** saatavilla koneluettavassa rakenteisessa muodossa (esim. excel-taulukkona eikä vain kuvana siitä)
*** kuten (2) mutta järjestelmäriippumattomassa formaatissa (esim. CSVnä eikä excelinä)
**** kaikki edellämainittu ja lisäksi: käytetty W3Cn avoimia standardeja (RDF ja SPARQL) identifioimaan tietoja, niin että julkaistuun dataan voidaan viitata
***** kaikki edellämainittu ja lisäksi: linkitä datasi muiden dataan liittääksesi sen oikeaan kontekstiin
Brittiläinen Nigel Shadbolt arvioi esityksessään Online Information 2010 -konferenssissa, että tällä hetkellä suurin osa Britanniassa julkaistusta avoimesta datasta kuluu 2-3 tähden luokkiin.
Avattaessa dataa muiden käyttöön joudutaan pohtimaan lisensiointimalleja, joita ovat esim. Creative Commons CC0 1.0 Universal Public Domain Dedication eli ns. Zero Waiver (CC0) ja Public Domain Dedication and License (PDDL). Niiden avulla pyritään selventämään mitä kyseisellä datalla ylipäätään saa tehdä ja mikä on julkaisijan vastuu suhteessa sitä hyödyntäviin sovelluksiin.
Avoin bibliografinen data
Open Bibliographic Data (OBD) on Linked Open Datan erityisalue, jossa keskeisinä kysymyksinä ovat bibliografisen datan uusiokäytön periaatteet ja MARC > RDF konversiokysymykset.
Open Bibliographic Data Flyerissa, jonka on julkaissut Open Knowledge Foundationin (OKF) Working Group on Open Bibliographic Data, on lueteltu sen hyötyjä:
- Varmistaa että bibliografisen datan valtavaa määrää hyödynnetään mahdollisimman paljon
- Ylläpitää ja kasvattaa kirjastojen merkitystä lisäämällä niiden näkyvyyttä internetissä ja semanttisessa webissä
- Laajentaa bibliografisen datan luontiin, rikastamiseen ja korjaamiseen osallistuvien joukkoa
- Mahdollistaa uusien bibliografista dataa hyödyntävien palvelujen ja/tai sovellusten kehittämisen, mikä hyödyttää sekä tutkijoita, kirjastonkäyttäjiä että yhteiskuntaa laajemminkin
Amerikkalainen kirjastoalan konsultti Karen Coyle korosti Online Information 2010 -konferenssissa pitämässään avauspuheenvuorossa, että bibliografisen datan avaaminen ei mitenkään riko tai tuhoa alkuperäistä dataa, vaan tuo sille vain lisäarvoa.
Bibliografisen datan julkaisemista varten on jo valmistunut JISCin rahoituksella kattava ohjesivusto Open Bibliographic Data Guide, jossa käsitellään mm. lisensiointia ja muita juridisia näkökohtia, mahdollisia kuluja ja säästöjä, käytännön vaikutuksia työprosesseihin, työn määrään ja ammattitaitoon sekä formaatteja ja muita teknisiä kysymyksiä.
Apuvälineitä bibliografisen datan avoimeen julkaisemiseen on niitäkin jo olemassa – esimerkiksi Internet Archiven Open Library -projekti tarjoaa tällaisen julkaisualustan ja Suomessa varsinkin FinnONTO-hankkeesta tunnettu Semanttisen laskennan tutkimusryhmä SeCo on myös kehitellyt ratkaisuja tähänkin.
Avauksia kirjastokentällä
Avointa bibliografista dataa on mahdollista lähestyä kahdesta näkökulmasta: joko vain avata se muiden käyttöön tai hyödyntää sitä myös itse.
Kongressin kirjasto on ollut edelläkävijä avatessaan auktoriteettitietonsa vapaasti käytettäväksi RDF-muodossa. Myös Saksan kansalliskirjasto on avannut tänä vuonna auktoriteettidatansa vapaasti käytettäväksi ja aikoo jatkossa avata kaiken bibliografisen datan. Samalla se on kehittämässä tätä tarkoitusta varten aivan uudenlaista lisensiointimallia.
British Library on jo jonkin aikaa tarjonnut dataansa vapaasti tutkimuskäyttöön, ja on vastikään julkaissut sen myös avoimesti Internet Archiven Open Library -palvelun kautta.
Toisaalta avoimesta linkitetystä datasta voisi olla apua myös kirjastoille itselleen.
Aiheesta oli pari alustusta ELAG 2010 -konfrenssissa, joka pidettiin Helsingissä viime kesänä. Esitykset herättivät innokasta keskustelua, jossa äärimmillään ehdittiin jo julistaa MARC-formaatti kokonaan kuolleeksi.
Käytännön toteutuksia on jo tuotannossa. Esimerkiksi Ruotsin yhteisluettelon LIBRISin uusi käyttöliittymä perustuu tähän teknologiaan – se julkistettiin jo vuonna 2008 ja lienee näin ollen maailman ensimmäinen kirjastoluettelo, joka on julkaistu kokonaisuudessaan linkitettynä datana. Käytännössä tämä tehtiin luomalla bibliografisiin ja auktoriteettitietueisiin cool HTTP URIt (käyttämällä apuna MARCin kenttää 001). Lisäksi datan yksittäisiin elementteihin on generoitu linkkejä, jotka johtavat pääasiassa LIBRISin muihin tietueisiin mutta myös esimerkiksi Kongressin kirjaston subject headingeihin, Wikipediaan ja sen tietämyskantaan DBpediaan.
LIBRIS oli jo tarjonnut dataa perinteisten rajapintojen kuten Z39.50n, SRUn ja OAI-PMHn kautta sekä myös web service -rajapinnan kautta MARCXML, Dublin Core, Json, RIS ja MODS -formaateissa. Nämä formaatit tarjoavat kuitenkin vain ja ainoastaan dataa, joka sisältyy alkuperäiseen MARC-tietueeseen. Linkitetty data tarjoaa tähän olennaista lisäarvoa.
Ajan myötä toivomukset saada vielä uusia rajapintoja muihinkin kuin kirjastojärjestelmiin alkoi saada sellaiset mittasuhteet, että kirjasto ei pystynyt enää vastamaan kysyntään. Oli helpompi avata koko data.
Tarkempi tekninen selostus LIBRISin ratkaisuista on julkaistu Martin Malmstenin artikkelissa Making a Library Catalogue Part of the Semantic Web, joka on samalla hankkeen loppuraportti. Siitä, miten muut ovat hyödyntäneet LIBRISin avoimia rajapintoja, voi lukea esimerkiksi heidän kehittämisblogistaan.
Toinen konkreettinen kuvaus uuden sovelluksen rakentamisesta avoimen datan periaatteella on tsekkiläisen Jindrich Mynarzin artikkeli Linked Data as a Library Data Platform – A Proof of Concept from National Technical Library of Czech Republic. Hän piti aiheesta myös esityksen Helsingin ELAGissa.
Suomessa ainakin Helsingin kaupunginkirjasto on julkaissut bibliografisen datansa avoimena ja tämänvuotisessa Apps4finland -kilpailussa oli jo mukana yksi sitä hyödyntävä sovellus. Myös kirjastot.fin oma LABS on tehnyt erilaisia kokeilusovelluksia linkitetyn datan avulla.
MARCin uudet suhteet
MARC-data on sellaisenaan jo tähtiluokituksen tasoa 3, mutta senkin koodisto lienee ulkopuolisille suhteellisen haasteellinen selvitettävä. Tästä syystä suositellaan, että data konvertoitaisi jo valmiiksi RDF/XML -formaattiin.
Miten sitten saadaan – Martin Malmstenia siteeratakseni – kirjastodata ”puhumaan RDFää”?
Hyvä perusluento asiasta on Talisin teknologiaevankelistan (kyllä, tämä on todellakin hänen tittelinsä) Rob Stylesin esitys Linked Bibliographic Data viimekesäisessä Linked Data and Libraries -konferenssissa.
Hän lähtee liikkeelle puhtaasta MARC-datasta, ”kääntää” ensin MARC-koodit selväkielelle, hajottaa ne sen jälkeen erilaisiksi kokonaisuuksiksi (tekijätiedot, teostiedot, aihetiedot) ja alkaa sitten yhdistellä näitä palasia uudelleen muiden palasten kanssa erilaisilla suhteilla. Lopulta hän on luonut aivan uuden maailman, joka on enemmän kuin osiensa summa.
Hetkinen. Kuulostaako sittenkin jo jotenkin tutulta?
Mitä tarkemmin näitä malleja katsoo, sitä selkeämmin niistä nousevat esille samat pyrkimykset kuin RDAssa ja FRBRssäkin: elementtien suhteet toisiinsa. Linkitetyn datan mallit eivät siis mitenkään ole ristiriidassa kirjastojen kuvailukehityksen kanssa, päinvastoin.
Tässä samaisessa Tietolinjan numerossa on Marjatta Autio-Tuulin ja Marja-Liisa Seppälän artikkeli, jossa asiaa käsitellään tarkemmin RDAn näkökulmasta.
Lisätietoa ja lähteitä
Avoimen bibliografisen datan kehittämistyötä pyrkii koordinoimaan maailmalla kaksi keskeistä toimijaa:
- W3C Library Linked Data Incubator Group
http://www.w3.org/2005/Incubator/lld/ - Open Knowledge Foundationin (OKF) Working Group on Open Bibliographic Data
http://wiki.okfn.org/wg/bibliography
Hyödyllisiä käytännön ohjeita löytyy sivustolta:
- JISC Open Bibliographic Data Guide
http://obd.jisc.ac.uk/
Kirjastodataa:
- British Library: Free Data Services
http://www.bl.uk/bibliographic/datafree.html - Deutsche Bibliothek: The Linked Data Service of the German National Library
http://www.d-nb.de/eng/hilfe/service/linked_data_service.htm - Library of Congress: Authorities & Vocabularies
http://id.loc.gov/authorities/about.html - Internet Archive Open Library Data (sis. mm. British Libraryn datan)
http://www.archive.org/details/ol_data - LABS.kirjastot.fi
http://labs.kirjastot.fi
Muita lähteitä:
- Bermes, Emmanuelle: Linked Data – and why we (librarians) should care. (esitys IFLAn pre-konferenssissa 2009)
http://www.slideshare.net/Figoblog/linked-data-and-why-we-librarians-should-care - Berners-Lee, Tim: Linked Data
http://www.w3.org/DesignIssues/LinkedData.html - Berners-Lee, Tim: On the Next Web (a TED talk)
http://www.ted.com/talks/tim_berners_lee_on_the_next_web.html - Danowski, Patrick: Open Bibliographic Data (esitys ELAG 2010-konferenssissa)
http://www.slideshare.net/PatrickD/open-bibliographic-data-elag2010 - Linked Data and Libraries -konferenssin (London, July 2010) esitykset
http://blogs.talis.com/nodalities/2010/08/linked-data-and-libraries-almost-like-being-there.php - Malmsten, Martin: Making a Library Catalogue Part of the Semantic Web
http://www.kb.se/dokument/Libris/artiklar/Project%2520report-final.pdf - Söderbäck, Anders & Malmsten, Martin: LIBRIS – Linked Library Data. Nodalities Magazine, November/December 2008.
http://www.talis.com/nodalities/pdf/nodalities_issue5.pdf (ss. 20-21) - Mynarz, Jindrich: Linked Data as a Library Data Platform – A Proof of Concept from National Technical Library of Czech Republic (esitys ELAG 2010 -konferenssissa)
http://www.slideshare.net/jindrichmynarz/linked-data-as-a-library-data-platform-4464958
laajempi artikkeli samasta aiheesta http://bit.ly/c1iJl9
Kirjoittajan yhteystiedot
Laila Heinemann, atk-erikoistutkija
Kansalliskirjasto / Kirjastoverkkopalvelut
PL 26, 00014 HELSINGIN YLIOPISTO
sähköposti: laila.heinemann (at) helsinki.fi